Wiktionary:Beer parlour/2017/January
Reconstructed Latin Words
[edit]So what I'm proposing is to rename this section, which deals with reconstructed Vulgar Latin verbs, nouns, etc. to Proto-Romance and apply the proper phonology for that, which has also been reconstructed in the same way, i.e. via applying the comparative method to modern Romance Languages. The result reflects the last common ancestor of all of them, which was Proto-Romance by definition. Vulgar Latin is a much broader term which can cover centuries before the period in question; the about page for Vulgar Latin even feels the need to specify that 'the form of Vulgar Latin that is considered in Wiktionary's entries is primarily the latest common ancestor of the Romance languages.' So I think we're essentially in agreement on this point.
One benefit of the Proto-Romance label is that we can have a better idea of the phonology to use.
Let's take a look at some of the issues concerning the current phonology:
1) Mulgo = [molgo]
The first [o] reflects only the Italo-Western Romance pronunciation, while Sardinian and Eastern Romance are both given with [u].
That is because they all came from Proto-Romance [ʊ].
2) Festizo = [ˈfes.tʲe.zo]
The source cited for this page indicates that the < z > represents [ʤ]. That section then refers to a previous one that mentions that this evolved along the lines [dj] > [j] and sometimes to [ʤ] depending on context. For Proto-Rom. I'm fairly certain that we're still at the [dj] stage. In either case, [z] is wrong. Also the bot has automatically palatalized the t to tʲ, which can't be right as all the derivatives show that it was a simple [t].
3) Desidium = [deˈse.ðe.õ]
The consonant ð did not exist in the period in question (2-4th. centuries AD) according to any source I could find. Looking at this phonological timeline for the French language, the intervocalic lenitions (which is what we're seeing here with desi[d]ium -> desi[ð]ium ) happened during and after the 'Proto-Gallo-Ibero-Romance' period, so essentially it affected the areas of France and Spain. This would also explain why the consonant doesn't appear in Italian, which keeps e.g. the [t] in vi[t]a, which became [ð] in Spanish/Portuguese and early Old French (and disappeared in later French).
I can't find a source saying that nasal vowels existed at all in Proto-Rom. so to me that final õ is suspect. For whatever reason, the bot has failed to make the second (prevocalic) < i > into [j], as it usually does. Also, since the mergers of [ɪ] into [e] and [ʊ] into [o] had not occurred yet in PR, the overall pronunciation here would be along the lines of [deˈsɪdjʊ].
In sum, the section would more accurately be called Proto-Romance and its current phonology is sketchy and could stand to be replaced with the one linguists have come up with for that period. — This unsigned comment was added by Excelsius (talk • contribs).
This page is being populated by the new {{ISBN}} template. Entries in this category have ISBNs that do not pass the checksum test or are possibly incorrectly formatted and cannot be recognized as valid. They will need to be researched carefully and replaced with the correct numbers. DTLHS (talk) 7:50 pm, Today (UTC−8)
- Module:check isxn This module is crosslinked at d:Q21856723 (but, of course, en.wikt doesn't have interwiki links through d: yet). It provides functionality for other standardized numbers such as ISSNs but I didn't copy over any templates for that. —Justin (koavf)❤T☮C☺M☯ 05:00, 4 January 2017 (UTC)
Stable 20 % growth in active editors?
[edit]From stats:wiktionary/EN/PlotEditorsZZ.png it looks like around the end of 2015 there was a 20 % jump in active editors which has been sustained until now. Most of the growth seems to come from the English Wiktionary: stats:wiktionary/EN/PlotEditorsEN.png. If we look at the detailed statistics (stats:wiktionary/EN/TablesWikipediansEditsGt5.htm), we see that en.wikt has had around 300 monthly active editors for years, but since April 2016 is around 390. October 2016 has been the first month ever with over 400 active editors (429); while deletions can reduce this number upon recalculation from updated dumps, I think it's likely to stay above 400.
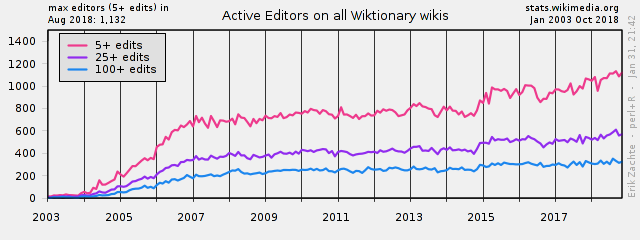{kind=link}
{kind=link}
Do you agree this is real growth and not just a statistical glitch? Do you have any idea what's going on? --Nemo 08:13, 4 January 2017 (UTC)
- Because we are cool. Maybe also because Wiktionary is starting to become useful in reading and not only fun to edit. People find answers here and can just add small hints and not create a whole new page on there first edit. It is easier then to become a regular editor. Another plausible explanation is people coming from Wikipedia because of fights there or because of Wikidata improvements. Finally, it may come from the multiple efforts people are doing to talk about Wiktionary all over the world, like by doing a talk at Wikimania or creating content on Youtube about the project. In short: Wiktionary is becoming trendy
 Noé (talk) 16:25, 4 January 2017 (UTC)
Noé (talk) 16:25, 4 January 2017 (UTC)
- Maybe we could find some of these supposed new editors and ask them which of those reasons, if any, they have for being here. DTLHS (talk) 16:29, 4 January 2017 (UTC)
- I started editing frequently around the end of 2015, so I suppose I'm part of this growth, but my case was mainly due to a revival of my personal interest in languages and etymology. Turning to Wiktionary came naturally due to its etymologies and the breadth of its coverage of old languages (especially Latin). — Kleio (t · c) 15:49, 7 January 2017 (UTC)
- Maybe we could find some of these supposed new editors and ask them which of those reasons, if any, they have for being here. DTLHS (talk) 16:29, 4 January 2017 (UTC)
- When did the translation editor java script gadget get added? That seems to be something that lots and lots of people use between 5 and 100 times. - TheDaveRoss 20:59, 5 January 2017 (UTC)
- I think User:Conrad.Irwin started working on that (User:Conrad.Irwin/editor.js) on 9 April 2009. —Stephen (Talk) 11:29, 6 January 2017 (UTC)
- Wiktionary, particularly en.WT, has a developing reputation amongst academicians. Language students and academics, and hobbyists of same, are likely our largest contributing pool as our content is most related to their field(s) of interest. Chicken, egg. (This is, imo, a failing of the WT project.) - Amgine/ t·e 17:09, 8 January 2017 (UTC)
- @Amgine: I'm confused--how would attracting specialists be a bad thing? Do you think this project is too difficult for newcomers or lay editors? —Justin (koavf)❤T☮C☺M☯ 17:57, 8 January 2017 (UTC)
- Wikimedians work on what interests them. A group of specialists and academics are interested in, and build, rather different things than a lay person who is looking for a dictionary. - Amgine/ t·e 21:17, 8 January 2017 (UTC)
- @Amgine: I agree that this project is the most intimidating. I encourage totally new users to check out q:, since it is so easy to edit and has so few rules and templates. This would be the last project because of its complexity. —Justin (koavf)❤T☮C☺M☯ 21:51, 8 January 2017 (UTC)
- So all the growth is thanks to my Wiktionary special on the Wikimedia research newsletter? ;-) I would like to believe so, but I'm not sure there are so many academics contributing. If there are, they should be pointed to the conclusion of the GLAWI paper, which I quote again: «Wiktionary serves its purpose well by having little constraints and maximising participation, while standardization can be performed downstream».
- Nowadays, I suspect that any academic who finds Wiktionary too simple will spend time on d:Wikidata:Wiktionary or custom SemanticMediaWiki wikis, rather than try making Wiktionary gradually more similar to what they want. --Nemo 16:09, 11 January 2017 (UTC)
- @Amgine: I agree that this project is the most intimidating. I encourage totally new users to check out q:, since it is so easy to edit and has so few rules and templates. This would be the last project because of its complexity. —Justin (koavf)❤T☮C☺M☯ 21:51, 8 January 2017 (UTC)
- I agree with DTLHS, let's list the new active users and write to a sample of them. :) If someone wants to work on this, I can help with database queries. Nemo 16:09, 11 January 2017 (UTC)
- @Nemo_Bbis: are you thinking of OmegaWiki in particular or do you know of other examples? —Justin (koavf)❤T☮C☺M☯ 16:24, 11 January 2017 (UTC)
- Wikimedians work on what interests them. A group of specialists and academics are interested in, and build, rather different things than a lay person who is looking for a dictionary. - Amgine/ t·e 21:17, 8 January 2017 (UTC)
- @Amgine: I'm confused--how would attracting specialists be a bad thing? Do you think this project is too difficult for newcomers or lay editors? —Justin (koavf)❤T☮C☺M☯ 17:57, 8 January 2017 (UTC)
- I'm not sure when this started happening, but on my iOS device, whenever I use the "look up" feature (which was changed from Define with the release of iOS 10), the Wiktionary entry appears with other dictionaries. Maybe the Wiktionary widget was added sometime in August, since there was an increase in page views starting in August 2016 (here). More page views would eventually draw more editors. Also, Google now gives Wiktionary entries considerable weight in its search algorithm; they appear in the first page for many definition searches and often as in the first three results for Latin searches (in my experience). I'm not sure how to tell when Google implemented that change. The problem with ascertaining these things is that there are many independent variables, and we can only measure one dependent variable—the progress of the data in Wikistats. Icebob99 (talk) 05:36, 29 January 2017 (UTC)
Sixth LexiSession: car
[edit]Monthly trend topic is car. You are invited to participate in the common goal to discover what can be gathered around the word car! There is already a Wikisaurus on vehicle and a Wikisaurus on automobile but there is still a lot to describe on pimping cars like spoiler, hubcap and vinyl roof. Plus, illustrations are welcome for every parts of cars and we may also imagine figures to illustrate the internal structure of vehicules!
This collaborative experiment is still running without any guide nor direction. You're free to participate as you like and to suggest next months topic. If you do something, please report it here, to let people know you are involve in a way or another. Hope there will be some people interested by this one ![]() Noé (talk) 16:40, 4 January 2017 (UTC)
Noé (talk) 16:40, 4 January 2017 (UTC)
Redirect CJK & Kangxi radicals to common CJK characters
[edit]As we discussed around October 2016 about to redirect halfwidth & fullwidth characters to common ones, CJK & Kangxi radicals are in the same situation. The CJK & Kangxi radicals appear same as its common CJK characters. I suggest to redirect them either. For example, ⼀ U+2F00 KANGXI RADICAL ONE should be included into 一 U+4E00 CJK UNIFIED IDEOGRAPH-4E00 (and add character info too), and so on. Except only if a radical does not have same common character (I think I see some), so it can have its individual page. I am starting to do this at Thai Wiktionary. [1] How do you think? --Octahedron80 (talk) 02:50, 7 January 2017 (UTC)
PS. I also think about CJK compatible characters to be redirected. But I am not sure whether wiki system will allow to do that. --Octahedron80 (talk) 03:19, 7 January 2017 (UTC)
- I'm pinging @I'm so meta even this acronym in case he's interested, because this is about character boxes and redirects.
- Support both types of redirect wherever applicable. The wiki software apparently already redirects automatically all the codepoints in "CJK Compatibility Ideographs" and "CJK Compatibility Ideographs Supplement", but I'd support adding the second character box in all these entries.
- Apparently, things like the ⼀/一 are just basically two codepoints for the same character. Unrelatedly, I naturally support keeping separate entries for simplified/traditional Chinese, which is a different thing.
- I generally support redirecting any separate codepoints that are basically variations of the same single character. For example, I redirected ❣ ("HEAVY HEART EXCLAMATION MARK ORNAMENT") to ! because when you write an exclamation mark with a large heart style, it's still an exclamation mark. As I said in the last vote, if we define "D" as "Fullwidth form of D", this would not make a lot of sense if Wiktionary were printed or if the reader does not care about separate codepoints, because it's just a typographical variant. We might as well define "D" as "Comic Sans MS form of D".
- See Category:Character variation redirects. I believe that currently, all the targets of these redirects have multiple boxes to account for the character variations. If the boxes are not enough (they are geeky and may require a bit of knowledge of Unicode to read properly), we may want to eventually add usage notes en masse to all these entries, explaining the differences of codepoints. --Daniel Carrero (talk) 07:41, 7 January 2017 (UTC)
- I
 Oppose this. The "Kangxi Radicals" and "CJK Radicals Supplement" Unicode blocks specifically represent ⾞ as a symbol used in classification of Chinese characters rather than 車 as a morpheme meaning "cart". —suzukaze (t・c) 14:48, 7 January 2017 (UTC)
Oppose this. The "Kangxi Radicals" and "CJK Radicals Supplement" Unicode blocks specifically represent ⾞ as a symbol used in classification of Chinese characters rather than 車 as a morpheme meaning "cart". —suzukaze (t・c) 14:48, 7 January 2017 (UTC)
- I
- What is the difference? The radicals are only used as dictionary indices collecting for convenience. And we are the dictionary makers here. ;-) --Octahedron80 (talk) 14:53, 7 January 2017 (UTC)
- "Kangxi Radical Cart" is a "translingual symbol" in the purest sense. Usage of "Kangxi Radical Cart" in text semantically differs from usage of "CJK Unified Ideograph 8ECA", unlike usage of halfwidth vs. fullwidth characters. —suzukaze (t・c) 14:59, 7 January 2017 (UTC)
- In addition, not all of them have "CJK Unified Ideograph" counterparts, like ⺀ "CJK Radical repeat". —suzukaze (t・c) 15:04, 7 January 2017 (UTC)
- [edit conflict] See also chapter 18 of the Unicode Standard, page 20. —suzukaze (t・c) 15:09, 7 January 2017 (UTC)
- It's just the Unicode name to call it something individually; it is not very special. If you dig a bit, you will find that they are already mapped with common characters on compatible mode. So it is not so wrong to use common 'car' as Kangxi 'car', and vice versa. Yes, some of them have no common character as I told above; we still keep them. --Octahedron80 (talk) 15:07, 7 January 2017 (UTC)
- @Octahedron80: Regardless of the merits, if any, of redirecting these entries (which I support doing, as I said above), please wait some time (maybe a couple of weeks) before creating more redirects. I see that you redirected a few pages already, but we might want to discuss this first. Before redirecting the full/halfwidth characters, I waited 3 months, by my count: I created a one-month vote that started two months after I had created a discussion with the initial proposal. --Daniel Carrero (talk) 15:19, 7 January 2017 (UTC)
- ^ I also have a lot of work at thwikt with the same topic. So I must recess from enwikt for now. --Octahedron80 (talk) 15:27, 7 January 2017 (UTC)
- @Octahedron80: Regardless of the merits, if any, of redirecting these entries (which I support doing, as I said above), please wait some time (maybe a couple of weeks) before creating more redirects. I see that you redirected a few pages already, but we might want to discuss this first. Before redirecting the full/halfwidth characters, I waited 3 months, by my count: I created a one-month vote that started two months after I had created a discussion with the initial proposal. --Daniel Carrero (talk) 15:19, 7 January 2017 (UTC)
- Are there any paper dictionaries that define 車 as "cart" but which keep ⾞ separately defined as something like "This a symbol used in classification of Chinese characters! Don't confuse it with 車, which is absolutely different!"? On the contrary, are there any sources (even written in Chinese) that assign both uses to the same character, by saying something like: "you can use the cart symbol (車) as a way to classify Chinese characters"? --Daniel Carrero (talk) 15:24, 7 January 2017 (UTC)
- Anyone who would explicitly distinguish them in a traditional dictionary must be mad. But we're not a traditional dictionary.
- In common use, the "CJK Unified Ideograph" character is regularly used to represent the concept of the Kangxi radical (such as at 1 or 2) and most people probably don't even know of the existence of the "Kangxi Radical" Unicode block.
- Many dictionaries include a "Kangxi radical" definition for the character. For example, [2] (a dictionary by the Taiwanese Ministry of Education) defines the character 儿 as
- an alternative form of 人 (rén)
- one of the 214 radicals.
- Accordingly, in September I added similar definitions to the "Translingual" section of "CJK Unified Ideographs" entries here while creating entries for "Kangxi Radicals" characters.
- See the Unicode Standard chapter I linked to above.
- The halfwidth & fullwidth characters (and other outdated symbols) exist in Unicode with the same reason, backwards compat. Why not these radicals can't do the same way :-) . --Octahedron80 (talk) 15:41, 7 January 2017 (UTC)
- These Unicode symbols have a difference explicitly defined by Unicode itself. —suzukaze (t・c) 15:49, 7 January 2017 (UTC)
- (Don't blame me.) I read your message many times. It sounds like you support in 1-3 as: After redirecting, we could include all available definition of a same appearent character in one page, even radical's and compat's. Because this is not traditional dict, no one would go mad. After including, we would have one more character info that still contains the radical's information, as the character itself and its categories, like the old ones. So nothing would be missed. --Octahedron80 (talk) 16:31, 7 January 2017 (UTC)
- @Suzukaze-c: Naturally, feel free to disagree with me, but personally I still support redirecting the entries as Octahedron80 suggested. You did say that it's madness for traditional dictionaries to separate between 車/車; apart from the "traditional dictionary" label, you did not state any reason to justify the madness, (I'm not sure if my edit to $ which you linked implies something) but for one I believe that it really is a bad idea for print dictionaries to do so, because just by looking at the shape of 車/車 it's not possible to tell the difference between them. Still, if print dictionaries can't have these as separate entries for that reason, then it means that if Wiktionary were to be printed in the future (which it might be, either as an official Wikimedia project or as a legally CC-licensed derivative by any person), then it's going to be a "traditional" dictionary too in some sense, and it would be a bad idea for Wiktionary to keep 車/車 separated, too.
- You linked to your edits on the entries 玄 and ⽞, the "main" one having a sense linking to the "radical" one. On principle, I applaud the idea of building a system to organize the characters, including your effort to create Template:mul-kangxi radical-def to link the entries. But I think that merging them is better: if we were going to have a whole sense in the "main" entry for the radical, then clicking on the separate "radical" entry did not seem able to provide very much else for the reader besides having an additional link to Index:Chinese radical/玄. We can just add the index link in the "radical" sense of the "main" entry and be done with it; this should be able to save one click from the reader's time.
- I have the impression that, no matter whether the reader tries to access 玄 or ⽞ at first (as in, they might have copied any of those from a separate website), the information on the whole "main" entry is probably going to be of interest; the "radical" page basically just had a sense linking back to the "main" page. The "main" entry contains the etymology, images and links to external databases. The "radical" entry did not have these things and was therefore incomplete; if it had these things, they would be a repetition of what can be found in the main "entry", and therefore reading it might be considered a waste of time.
- As you said, in the dictionary you linked to, 儿 (the "main" entry) is defined as "one of the 214 radicals"; that dictionary does not use ⼉ (the "radical" entry) for that definition. That does not invalidate the existence of the "radical" codepoint, but it does serve as additional evidence for the hypothesis that 儿 and ⼉ are the same character; possibly, there are applications that sort the "radical" in a different way (I didn't check) and/or have other hidden properties of these characters; the "radical" sense in the "main" entry should probably state "use the codepoint ⼉ for the radical when a semantic distinction is needed". This usage instruction came from the page 21 of the Unicode policy you linked. It says: "The characters in the CJK and KangXi Radicals blocks are compatibility characters. Except in cases where it is necessary to make a semantic distinction between a Chinese character in its role as a radical and the same Chinese character in its role as an ideograph, the characters from the Unified Ideographs blocks should be used instead of the compatibility radicals." --Daniel Carrero (talk) 18:40, 7 January 2017 (UTC)
- Thanks for the ping, Daniel Carrero. Primâ facie, I would support this, but suzukaze-c's opposition and this paragraph from page 688 of the Unicode Standard: “Characters in the CJK and KangXi Radicals blocks should never be used as ideographs. They have different properties and meanings. U+2F00 kangxi radical one is not equivalent to U+4E00 cjk unified ideograph-4e00, for example. The former is to be treated as a symbol, the latter as a word or part of a word.” make me hesitant. How would this proposal affect KangXi radicals that are visually distinguishable from their equivalent CJK unified ideographs? — I.S.M.E.T.A. 23:03, 7 January 2017 (UTC)
- re. ISMETA: There are no "Kangxi Radicals" characters that are visually distinct from the "Unified Ideograph" equivalent (unless the font designer is weird or you get picky), but there are multiple characters in "CJK Radicals Supplement" that may map to a single "Unified Ideograph" character (⻌⻍⻎→辶) and some that may map to multiple or no Unified Ideographs.
- re. Daniel: Think of it this way: the character 儿 (Unified Ideograph) encompasses usage as both a radical and a morpheme used in language and running text while the character ⼉ (Kangxi Radical) is solely for usage as a radical. —suzukaze (t・c) 02:49, 8 January 2017 (UTC)
- @suzukaze-c: OK, so is your point that, because there exist both multiple radicals in surjective correspondence with one ideograph (e.g. ⻌, ⻍, ⻎ → 辶) and one radical in injective correspondence with multiple ideographs (e.g. ⽔ → 水, 𣱱), there is no way to do this consistently? — I.S.M.E.T.A. 15:06, 15 February 2017 (UTC)
It's based on the pre-1938 Latin alphabet with the following changes:
- Cyrillic orthography doesn't differentiate between ə and e (э and е) after n, ņ t, d, ʒ and j as the characters are used to indicate palatality.
- I've left ə for эand e for e in all such cases, since even if we found a way to automatize this as it's been done for Russian, there are too few resources to practically recover these distinctions.
- I've replaced the original transliteration of ш (s which is what с maps to as well) to ş (which щ maps to as well). In the literary dialect this sound occurs only in Russian loanwords, however some dialects have it in native words.
Does the community support this transliteration? Can I put it in operation? Crom daba (talk) 03:13, 7 January 2017 (UTC)
- I have no comments on Evenki specifically, but I'd like to request that whatever transliteration conventions we create, they be 1) documented, and 2) linked from the appropriate places, such as Wiktionary:About Evenki (which doesn't even seem to exist yet). A decent further addition might be 3) motivation for the particulars of the transliteration, if that's not too much of a bother. --Tropylium (talk) 16:11, 12 January 2017 (UTC)
- Done, thanks for not letting me off the hook without the documentation. Crom daba (talk) 04:01, 15 January 2017 (UTC)
Steps towards a policy on ... place names
[edit]It would help to have an official policy on place names. The current CFI talks around the issue but does not provide clear guidance: "Wiktionary articles are about words, not about people or places. Many places, and some people, are known by single word names that qualify for inclusion as given names or family names. The Wiktionary articles are about the words. Articles about the specific places and people belong in Wikipedia."
I think this is unhelpful to editors particularly less experienced members of the community. Editors risk investing a lot of time in articles that later get deleted - even without a formal policy change. That is off putting. I can see that in the past there has been some difficulty in achieving consensus but I would like to try again.
I would suggest that we start with a very simple policy to increase the chances of reaching agreement. My proposed policy statement is:
"The following place names meet the criteria for inclusion:
- The names of continents.
- The names of seas and oceans.
- The names of nation states.
- The names of primary administrative divisions (states, provinces, counties etc).
- The capital cities of nation states.
- The capitals of primary administrative divisions.
The community has not reached a consensus on place names/geographic features other than those listed above."
John Cross (talk) 19:10, 7 January 2017 (UTC)
- These rules would exclude major Dutch cities like Leiden, Eindhoven and Breda, Belgian cities like Leuven and Charleroi, and German cities like Cologne and Nürnberg. I think that would be absurd. —CodeCat 19:55, 7 January 2017 (UTC)
- My intention was that the policy was neutral on Cologne for example. John Cross (talk) 21:56, 7 January 2017 (UTC)
- IMHO it'd be good to just have a blanket acceptance of all placenames. Toponymy and other forms of onomastics should fall within Wiktionary's scope, I think. — Kleio (t · c) 22:40, 7 January 2017 (UTC)
- I'm inclined to agree with Kleio on this. I also dislike the use of the term nation state in this proposed policy statement; the nation state is a historically rather recent phenomenon (the 1648 Peace of Westphalia instituted it, according to the traditional account), so how does this policy affect Latin toponyms attested in Classical to Renaissance sources? — I.S.M.E.T.A. 23:11, 7 January 2017 (UTC)
- Agreed We could have Springfield 1.) a city in Illinois, 2.) a city in Oregon, etc. for common place names and The Hague would have info on the one municipality that has that name. Place names can have etymologies and will certainly be attested. —Justin (koavf)❤T☮C☺M☯ 23:12, 7 January 2017 (UTC)
- Are you saying we should have a separate definition (and translations) for each city in the US named Springfield? DTLHS (talk) 23:14, 7 January 2017 (UTC)
- @DTLHS: If they all have the same etymology (which these would), then I think it's fair to say "A common city name found in Illinois, Ohio, ..." —Justin (koavf)❤T☮C☺M☯ 23:24, 7 January 2017 (UTC)
- I would agree that for common city names, there should generally be a single entry, except where one particular usage is more important. Our current entry for Springfield is a good example. Capital cities should be noted individually because the capital is often used synonymously with the government of the entire jurisdiction. bd2412 T 00:05, 8 January 2017 (UTC)
- We have Wiktionary:Place names as a list (under construction) of different types of places of each country for further analysis. Also, I agree with Kleio on this: "IMHO it'd be good to just have a blanket acceptance of all placenames." --Daniel Carrero (talk) 00:14, 8 January 2017 (UTC)
- I too would agree to blanket acceptance of all place names. DonnanZ (talk) 00:29, 8 January 2017 (UTC)
- What is a place name? Would we accept names of streets and buildings? DTLHS (talk) 00:42, 8 January 2017 (UTC)
- This is a rule of thumb that can be discussed/changed by other people: I think I'd be fine with having all place names from continents and countries to cities, towns, neighborhoods, villages, etc.
- I guess we probably don't want names of buildings and streets here; although we do have Empire State Building and Harley Street. I wonder if we are going to keep only a few streets and buildings that are notable. --Daniel Carrero (talk) 01:43, 8 January 2017 (UTC)
- What is a place name? Would we accept names of streets and buildings? DTLHS (talk) 00:42, 8 January 2017 (UTC)
- I too would agree to blanket acceptance of all place names. DonnanZ (talk) 00:29, 8 January 2017 (UTC)
- We have Wiktionary:Place names as a list (under construction) of different types of places of each country for further analysis. Also, I agree with Kleio on this: "IMHO it'd be good to just have a blanket acceptance of all placenames." --Daniel Carrero (talk) 00:14, 8 January 2017 (UTC)
- I would agree that for common city names, there should generally be a single entry, except where one particular usage is more important. Our current entry for Springfield is a good example. Capital cities should be noted individually because the capital is often used synonymously with the government of the entire jurisdiction. bd2412 T 00:05, 8 January 2017 (UTC)
- @DTLHS: If they all have the same etymology (which these would), then I think it's fair to say "A common city name found in Illinois, Ohio, ..." —Justin (koavf)❤T☮C☺M☯ 23:24, 7 January 2017 (UTC)
- Are you saying we should have a separate definition (and translations) for each city in the US named Springfield? DTLHS (talk) 23:14, 7 January 2017 (UTC)
- Agreed We could have Springfield 1.) a city in Illinois, 2.) a city in Oregon, etc. for common place names and The Hague would have info on the one municipality that has that name. Place names can have etymologies and will certainly be attested. —Justin (koavf)❤T☮C☺M☯ 23:12, 7 January 2017 (UTC)
- I'm inclined to agree with Kleio on this. I also dislike the use of the term nation state in this proposed policy statement; the nation state is a historically rather recent phenomenon (the 1648 Peace of Westphalia instituted it, according to the traditional account), so how does this policy affect Latin toponyms attested in Classical to Renaissance sources? — I.S.M.E.T.A. 23:11, 7 January 2017 (UTC)
Place names - 2nd attempt
[edit]I was really pleased with all the feedback I got on my 1st attempt here is attempt 2.
"The following place names meet the criteria for inclusion:
- The names of continents.
- The names of seas and oceans.
- The names of countries.
- The names of areas or regions containing multiple countries (e.g. Middle East, Eurozone).
- The names of primary administrative divisions (states, provinces, counties etc).
- The names of conurbations, cities, towns, villages and hamlets.
- The names of natural geographic features (e.g. deserts, mountains, rivers) which are notable (per Wikipedia:Notability).
The Community has not yet reached a consensus as to whether or not place names/geographic features other than those listed above should be included in Wiktionary."
I have avoided mentioning streets, tunnels, buildings etc.
John Cross (talk) 08:24, 8 January 2017 (UTC) (amended John Cross (talk) 08:36, 8 January 2017 (UTC))
- I think that if the name is a single word (e.g. Haymarket) then we should include it. If it is two or more words (e.g. Downing Street) then we should include it only if we can provide three or more usages of it in the usual sort of sources. SemperBlotto (talk) 08:57, 8 January 2017 (UTC)
- Probably not an issue, but it feels a bit odd for us to rely on a WP policy (notability) that is somewhat outside our control. Equinox ◑ 10:21, 8 January 2017 (UTC)
- What about place names that are linguistically interesting, but not otherwise "notable"? DCDuring TALK 17:00, 8 January 2017 (UTC)
- <nods> I think the notability question should be relevant to Wiktionary's sphere of interest. However, it does become a local problem to determine what is notable. E.g. I have several books on feature names and their origins of the west coast of North America from the late 19th and early 20th century, and most every named rock has a story of a shipwreck, confrontation, or other historic event in any of several dozen languages. - Amgine/ t·e 17:19, 8 January 2017 (UTC)
- What about place names that are linguistically interesting, but not otherwise "notable"? DCDuring TALK 17:00, 8 January 2017 (UTC)
- I think place names should be allowed, provided they meet CFI. I imagine that that would exclude almost all but the most notable street names, which would not be mentioned in any published works that are citeable (i.e. excluding reference books, maps, etc.). The number of such places would doubtlessly be enormous, but I see no harm in such entries, if people are willing to add them. Etymologies of even the most insignificant places can be interesting to those who live near it, and it would be kind of neat to eventually be able to search for any town in the world and find out how it got its name, etc. I have no strong feelings on including street names or non-notable towns and villages, but I support adopting John Cross's criteria. Andrew Sheedy (talk) 21:51, 8 January 2017 (UTC)
- Pretty much every city and town in the United States has a "Main Street", and I would hazard a guess that pretty much all of them that have local newspapers could meet CFI (news stories always name the street where something happened). Are we ready to have an English entry with more proper noun senses than water has translations? And definitions that mostly say "a street in <NAME OF A CITY OR TOWN>", at that. As for the laziness of users limiting quantity: we seem to attract more than our share of obsessive types who will literally add every permutation theoretically possible of everything unless someone stops them. Without an extremely clear and robust consensus about what is not permissible, we could find ourselves either with dozens of entries that look like the index of a large map book, or with boatloads of rfds- or both. Chuck Entz (talk) 04:27, 10 January 2017 (UTC)
- I support this as well, and feel similar to Andrew Sheedy on this. Etymology is lexically interesting, whether it's a common noun or a place name. So is pronunciation, which we should certainly also include. I would like John Cross to clarify whether subdivisions of cities are also included. This is important because the status of settlements can change: what was once a separate village can later become a suburb of a larger city. Since official status can change at any time, this might imply that includability of a term is temporary, and what was once includable might lose that status once its real-life status changes too. I think that's undesirable, so we should make our rules independent of the official status of any particular place.
- As for rivers in particular, we could adopt a different definition from notability, one based on how many places it flows through, or perhaps its length or water volume. These are more objective criteria. —CodeCat 22:57, 8 January 2017 (UTC)
- Well, I am far more interested in the water-related place names than the land-based ones. As a nautical buff I would suggest there are many reasons for a waterway to be notable for itself, even if it no longer exists. E.g. portions of the Zuiderzee such as this bight northwest of Amsterdam which no longer exists but certainly once had a name, the North Pacific Gyre which is a solely current-defined feature, and the Nahwitti Bar (which forms the western end of Goletas Channel between Vancouver and Hope Islands on the north-eastern coast of the former, named after the 'Nakwaxda'xw tribe whose native language is 'Nak̕wala Kwak'wala, part of the Northern Wakashan group.) - Amgine/ t·e 00:45, 9 January 2017 (UTC)
.jpg){kind=link}
I could probably support this, as long as the notability requirement were removed from point seven; we could have something like “The names of significant natural geographic features (e.g. deserts, mountains, rivers) which are notable (per Wikipedia:Notability).” — with “significant” allowing for fine-tuning by casuistry — instead. — I.S.M.E.T.A. 02:03, 10 January 2017 (UTC)
Place names - 3rd attempt
[edit]I was really pleased with all the feedback I got from previous attempts - here is attempt 3.
"The following place names meet the criteria for inclusion:
- The names of continents.
- The names of seas and oceans.
- The names of countries.
- The names of areas or regions containing multiple countries (e.g. Middle East, Eurozone).
- The names of primary administrative divisions (states, provinces, counties etc).
- The names of conurbations, cities, towns, villages and hamlets.
- Districts of towns and cities (e.g. Fulham).
- The names of inhabited islands and archipelagos.
- The names of other significant natural geographic features (such as large deserts and major rivers).
The Community has not yet reached a consensus as to whether or not the names of places and geographic features other than those listed above should be included in Wiktionary. There is currently no definition of "significant natural geographic features", but by way of an example, the twenty largest lakes in the world by surface area would each qualify. It is hoped that the Community will develop criteria over time to provide greater clarity and address matters not currently covered (for example the names of streets, buildings, tunnels). This policy is not intended to remove or reduce the requirement to find citations to support entries."
Please let me know what you think and please also help me to get this passed as a policy. Thank you.
John Cross (talk) 05:16, 12 January 2017 (UTC)
- Support. Andrew Sheedy (talk) 05:36, 12 January 2017 (UTC)
- I support everything except the requirement that islands be inhabited. — I.S.M.E.T.A. 08:21, 12 January 2017 (UTC)
- Support As well. I suppose that strictly speaking you can also add some copy about how other locations are assumed to not fit the criteria unless otherwise notable or somesuch. Maybe provide a higher threshold for attestation for (e.g.) streets than continents. —Justin (koavf)❤T☮C☺M☯ 08:26, 12 January 2017 (UTC)
- I support everything except the requirement that islands be inhabited. — I.S.M.E.T.A. 08:21, 12 January 2017 (UTC)
- Support. I would imagine that an uninhabited island could still qualify as a significant natural geographic feature. I'm not very worried about missing out on insignificant uninhabited islands. bd2412 T 23:58, 12 January 2017 (UTC)
Moved the draft text to an actual policy vote: https://en.wiktionary.org/wiki/Wiktionary:Votes/pl-2017-01/Policy_on_place_names
John Cross (talk) 05:12, 13 January 2017 (UTC)
The vote is now open: Wiktionary:Votes/pl-2017-01/Policy on place names John Cross (talk) 09:00, 21 January 2017 (UTC)
Vote: Trimming CFI for Wiktionary is not an encyclopedia 2
[edit]FYI, I created Wiktionary:Votes/pl-2017-01/Trimming CFI for Wiktionary is not an encyclopedia 2 to try again to remove misleading sentences from CFI. The first attempt was at Wiktionary:Votes/pl-2015-02/Trimming CFI for Wiktionary is not an encyclopedia.
@John Cross: The vote may help address some of the concerns you have raised recently. Note that the English Wiktionary inclusion policy about places names is actually at WT:NSE, and in practice leads to a fairly indiscriminate inclusion of a broad variety of place names. A vote that well indicates the English Wiktionary stance on place names is this: Wiktionary:Votes/pl-2010-05/Placenames with linguistic information 2. --Dan Polansky (talk) 08:46, 8 January 2017 (UTC)
@Dan Polansky thank you. I have voted. John Cross (talk) 20:27, 17 January 2017 (UTC)
POS orders I don't see anything specifying the order in which parts of speech should be placed in an entry. It seems like it goes something like Nouns→Verbs→Adjectives→...others? But I don't see a particular guideline. For instance, book has this order but the meanings of a bound collection of pages and codices is a lot more common than when the police enter a perp into the system (the verb form). At perfect, the adjective is before the adverb but this is also true of alphabetical order. Is there a preferred order for these entries? If so, it seems wise to state it explicitly. —Justin (koavf)❤T☮C☺M☯ 22:06, 8 January 2017 (UTC)
- They're ordered similar to senses: from common to rare. If they are ordered differently in an entry, it should be fixed. —CodeCat 22:43, 8 January 2017 (UTC)
- I always thought they were alphabetized (adjective, noun, verb). DTLHS (talk) 22:49, 8 January 2017 (UTC)
- Not usually. But I'd tend to put (say) the noun above the verb if the noun clearly came first — even though I prefer senses to be ordered by commonest current usage first. Equinox ◑ 22:50, 8 January 2017 (UTC)
- Like Equinox, I list POS sections in order of historical development (ditto for etymologies, in the case of homonyms), but I also do that for senses. AFAIK, there does not exist a consensus here vis-à-vis listing by historical development vs. frequency in common usage vs. alphabetical order vs. whatever other scheme; accordingly, "fixing" the order of POS sections and/or senses, as CodeCat suggests, is likely to prove controversial. — I.S.M.E.T.A. 01:58, 10 January 2017 (UTC)
Actualités: Monthly news of French Wiktionary in English
[edit]Hi all,
We continue to translate our monthly publication in English, for people interested in what is going on in French Wiktionary. This month, we relate a big project we have on Occitan, a language spoken in the Southern France, and give some wordplay in French. We're eager to receive your feedback and joke suggestions!
Every months, we provide a bunch of metrics and try to write a couple of paragraphs about our beloved project. This edition is the 21th issue, so it is allowed to drink alcool in US, something quite unusual for a periodical newspaper! Noé (talk) 00:01, 9 January 2017 (UTC)
- You forgot the link! [3] Equinox ◑ 00:09, 9 January 2017 (UTC)
- Do you have any insights about running large projects involving multiple editors? On this site it seems like people prefer to work alone and we don't really do anything like focus on a single language for a month. DTLHS (talk) 00:39, 9 January 2017 (UTC)
- The Occitan effort was part of a larger trans-project effort in continuing to develop content in one of the several primary regional languages of France. A parallel does not seem to exist in English, although possibly it might be if there were an effort to build content in Scots within en.WP and across the English wikimedia projects. - Amgine/ t·e 03:44, 9 January 2017 (UTC)
- Cornish, anyone? Equinox ◑ 15:54, 10 January 2017 (UTC)
Special:Contributions/Cherusk - Russian pronunciation edits
[edit]The edits of this user are currently under my scrutiny. Apparently they have unsuccessfully tried their luck on the Russian Wiktionary first. A regular knowledgeable user think it's a troll. Cherusk uses various non-standard or dialectal pronunciations, records own audio files. In some cases they are definitely wrong pronunciations. E.g. diff. Not sure if they are good faith edits. Considering a block if Cherusk doesn't stop. I don't have time to check each audio file but I can judge by the IPA edits. --Anatoli T. (обсудить/вклад) 03:21, 9 January 2017 (UTC)
Move character box images to Lua modules
[edit]See this diff.
I'd like to move all the images from the character boxes in each entry to Lua modules like Module:Unicode data/images/000. The charbox template ({{character info/new}}) is already prepared to find images in the modules.
Images to be moved: Category:Character boxes with images.
Rationale:
I think this would be a good idea, in case we want to use a database of images for each character somewhere else other than charboxes. In the future, I'm thinking of showing all the character images automatically in the Unicode tables like Appendix:Unicode/Latin Extended-A, if it's OK with everyone.
(ping: @I'm so meta even this acronym)
--Daniel Carrero (talk) 07:07, 10 January 2017 (UTC)
- @Daniel Carrero: This change seems entirely positive to me. Just to make sure I understand you properly, do the numbers in the PAGENAME for Module:Unicode data/images/000 (taking your example) denote the first three numbers common to the Unicode codepoints in the range for which that page lists data? That is, does that “000” denote “U+000##” (where the first zero denotes the Basic Multilingual Plane), meaning that Module:Unicode data/images/000 covers everything from U+00000 NULL to U+000FF LATIN SMALL LETTER Y WITH DIAERESIS (ÿ) — in this case the entirety of the C0 Controls and Basic Latin and C1 Controls and Latin-1 Supplement Unicode blocks? — I.S.M.E.T.A. 10:42, 10 January 2017 (UTC)
- @I'm so meta even this acronym. Good question. The answer is: I'm planning to imitate what is already done for character names. (unless there is any suggestion of a different naming system) We have modules like Module:Unicode data/names/000, Module:Unicode data/names/001, etc. The full list of modules is here: Module:Unicode data. That is, I'd like the first image module (the one you asked about: Module:Unicode data/images/000) to contain all codepoints from U+00000 NULL to 0x00FDA TIBETAN MARK TRAILING MCHAN RTAGS, which is the last assigned codepoint before the true upper limit: U+00FFF (unassigned). --Daniel Carrero (talk) 11:33, 10 January 2017 (UTC)
- @Daniel Carrero: Oh, my mistake: Plane 16 (consisting of the Supplemental Private Use Area-B block and two non-characters) comprises codepoints U+100000–U+10FFFF, so it makes sense for “000” to denote “U+000###”. I agree with that naming system. — I.S.M.E.T.A. 14:36, 10 January 2017 (UTC)
Now, I made the images appear in the Unicode appendices. See Appendix:Unicode/Basic Latin, Appendix:Unicode/Greek and Coptic, Appendix:Unicode/Yijing Hexagram Symbols, Appendix:Unicode/Arrows... --Daniel Carrero (talk) 18:41, 12 January 2017 (UTC)
- I noticed that @Octahedron80 copied the charbox template to the Thai Wiktionary (template link), which is great. Other Wiktionaries may want to copy the image modules, too. I created Category:character info/new with image as a temporary category with all the entries that are still using an "image=" parameter. I plan to delete the category once it's empty. There are still about 800 entries to go. --Daniel Carrero (talk) 10:34, 15 January 2017 (UTC)
![]() Done. I moved all charbox images from entries to modules. I removed the "image=" parameter from
Done. I moved all charbox images from entries to modules. I removed the "image=" parameter from {{character info/new}}, too. --Daniel Carrero (talk) 20:01, 9 February 2017 (UTC)
- Well done, Dan. That's some great work you've done there. :-) — I.S.M.E.T.A. 14:18, 15 February 2017 (UTC)
- Thank you. :) --Daniel Carrero (talk) 14:21, 15 February 2017 (UTC)
Chakavian, Kajkavian, Torlakian?
[edit]I would like to add entries for Chakavian words to Proto-Slavic entries but there is no language code that I can see for this language. Realistically speaking I would say this is its own Slavic language rather than a dialect of Serbo-Croatian, although it could be argued the other way. If we add Chakavian, we should also add Kajkavian and maybe Torlakian as well. Comments? Benwing2 (talk) 01:53, 12 January 2017 (UTC)
- @Ivan Štambuk and others have been content to add it as Serbo-Croatian with a dialect label. See Category:Chakavian Serbo-Croatian. Dialectal words can always be added as descendants where appropriate. —Μετάknowledgediscuss/deeds 01:02, 17 January 2017 (UTC)
What accentual notation should be used for Proto-Slavic?
[edit]@CodeCat I've been working on adding Proto-Slavic etymologies to Russian words and editing some of the Proto-Slavic reconstructed terms. Derksen 2008 uses the following notation:
- à = short rising (old acute on an originally long vowel, neoacute on an originally short vowel)
- á = long rising (neoacute)
- ȁ = short falling (circumflex in some syllables, or original short accent? circumflex if the vowel was originally long, short accent otherwise), e.g. *dȅsętь "ten", *dȅsnъ "right", *dȍma "at home"
- ȃ = long falling (circumflex in other syllables, or original short accent? circumflex if the vowel was originally long, short accent otherwise), e.g. *dȃrъ "gift", *dȏmъ "house"
The alternative notation is:
- ȁ (maybe?) = original short accent
- á = old acute
- ã = neoacute
- ȃ = circumflex
It could be argued that the latter notation is simpler, on the other hand it may not be accurate -- if you believe Derksen's view (maybe the Leiden view?), there was a never a time with three contrasting long-vowel accents, and the old acute was shortened prior to the shift that produced neoacutes.
Which should we use? Benwing2 (talk) 16:05, 12 January 2017 (UTC)
- I'd recommend using a notation that does not explicitly encode a particular tone contour or length, as these aspects often differed in various Slavic dialects. Instead, the tones should be indicated by their identity: the acute is the acute no matter if it's long or short. —CodeCat 16:10, 12 January 2017 (UTC)
- OK. I looked at WT:About Proto-Slavic and it does have a section on prosodic notation. However:
- It's pretty complicated, with six different accent types (seven if we count the macron for unstressed length). Furthermore, some of them (e.g. a̍, the word-final accent) don't display very well (e.g. in edit windows, at least on my Mac, where I just see boxes).
- This system isn't actually being used all that much. I took a look at various nouns in Category:Proto-Slavic nominals with accent paradigm b and many of them are using word-final à and ò, as in Derksen's and Wikipedia's system (see below).
- Do we want to simplify this system? Possibly we can use the system used in the noun declensions given in Wikipedia's Proto-Slavic, which seems pretty logical to me.
- Also, I am thinking of modifying the module that generates Proto-Slavic declensions to include accent marks. Sound OK to you? If we do this, it's another argument for using the Wikipedia system, since it would match up the declensions directly with that system. Benwing2 (talk) 19:27, 12 January 2017 (UTC)
- The stuff on WT:ASLA was mostly put there by Ivan Štambuk without there being any agreement on it. Is the Wikipedia system the same as the alternative notation you gave above? —CodeCat 19:55, 12 January 2017 (UTC)
- The stuff on Wikipedia is very similar to the Derksen system above but it uses ã for the neoacute instead of á or à (on both short and long vowels). The only place where the acute accent (á) is used is on final syllables, where both acute and grave occur. This is evidently indicating a length distinction (e.g. nominative singular nogà vs genitive singular nogý) but I don't know if this is standard or not. Note in particular that the genitive singular of class B žena is notated ženỳ whereas the genitive singular of class C noga is notated nogý. Benwing2 (talk) 00:27, 13 January 2017 (UTC)
- What is the reason for this difference, I wonder. —CodeCat 00:30, 13 January 2017 (UTC)
- I thought somewhat about this, and this is what I concluded:
- The length of Late Common Slavic final accented syllables is apparently reflected in the neo-circumflex in Slovenian (but nowhere else).
- The length of nogý but shortness of ženỳ happens because there was at one point a shortening of unstressed final syllables (this appears to be mentioned at the end of section 7 in [4]), and at the time, nogý was stressed but ženỳ was not. The final stress in class B occurred subsequent to this as a result of Dybo's law.
- The reason both nogà and ženà are short is a bit subtle, but apparently it's because the vowel was acute. At the time before Dybo's law, the forms were something like žȅna and nogá, with the final vowel acute. First, post-tonic acutes were lost (hence in žȅna) leaving a short vowel (per 7.13 in [5]), which remained short when the final syllable gained stress through Dybo's law. Later on, the acute was lost generally, producing a short rising vowel (9.2 in [6]).
- I'm sure not everyone subscribes to this theory, though. Benwing2 (talk) 01:26, 13 January 2017 (UTC)
- Why was the final vowel of *nogý not shortened the same way the vowel of *nogá was, when both had an acute? —CodeCat 02:10, 13 January 2017 (UTC)
- I thought somewhat about this, and this is what I concluded:
- What is the reason for this difference, I wonder. —CodeCat 00:30, 13 January 2017 (UTC)
- The stuff on Wikipedia is very similar to the Derksen system above but it uses ã for the neoacute instead of á or à (on both short and long vowels). The only place where the acute accent (á) is used is on final syllables, where both acute and grave occur. This is evidently indicating a length distinction (e.g. nominative singular nogà vs genitive singular nogý) but I don't know if this is standard or not. Note in particular that the genitive singular of class B žena is notated ženỳ whereas the genitive singular of class C noga is notated nogý. Benwing2 (talk) 00:27, 13 January 2017 (UTC)
- The stuff on WT:ASLA was mostly put there by Ivan Štambuk without there being any agreement on it. Is the Wikipedia system the same as the alternative notation you gave above? —CodeCat 19:55, 12 January 2017 (UTC)
- OK. I looked at WT:About Proto-Slavic and it does have a section on prosodic notation. However:
Out of curiosity, once you decide on a system, will someone implement the paradigms in the inflection templates (if that is possible)? —JohnC5 03:57, 13 January 2017 (UTC)
- Yes, I was thinking of doing exactly that. Benwing2 (talk) 05:54, 13 January 2017 (UTC)
- Great! I wish I could contribute more to expedite this discussion, but I am woefully uninformed in this matter. —JohnC5 06:06, 13 January 2017 (UTC)
- So I'm tentatively going with the Wikipedia notation. I corrected the comments above about it, and I'll repeat it:
- Great! I wish I could contribute more to expedite this discussion, but I am woefully uninformed in this matter. —JohnC5 06:06, 13 January 2017 (UTC)
Non-word-final vowels:
- à = short rising = old acute (only on an originally long vowel)
- ȁ = short falling (circumflex in some syllables, or original short accent; circumflex if the vowel was originally long, short accent otherwise), e.g. *dȅsętь "ten", *dȅsnъ "right", *dȍma "at home"
- ȃ = long falling (circumflex in other syllables, or original short accent; circumflex if the vowel was originally long, short accent otherwise), e.g. *dȃrъ "gift", *dȏmъ "house"
- ã = neoacute
Word-final-vowels:
- à = short rising
- á = long rising
Benwing2 (talk) 17:10, 13 January 2017 (UTC)
- See Module talk:sla-noun. I implemented a first pass at Proto-Slavic accents (only for hard masculine o-stems). Benwing2 (talk) 06:31, 15 January 2017 (UTC)
Old French
[edit]How are we meant to distinguish between Early Old French, Old French and Late Old French? Take these:
Latin: dirēctus
Vulgar Latin: drēctus
Early Old French: dreit /dreit/
Old French: droit /droit/
Late Old French: droit /drwe/
Middle French: droit /drwe/
French: droit /dʁwa/
There's only one Wiktionary page and that's for the Old French form, not the early or late ones. ÞunoresWrǣþþe (talk) 10:20, 14 January 2017 (UTC)
- As far as I know, Early Old French and Late Old French are both subsumed under just Old French. KarikaSlayer (talk) 15:44, 14 January 2017 (UTC)
- Perhaps labels could be used to distinguish between them, just like Ancient Greek has labels for Attic, Koine and Byzantine, for example. — Kleio (t · c) 18:30, 14 January 2017 (UTC)
- That'd be great, they really are rather different, mainly since they cover almost a millenium (like Greek)!ÞunoresWrǣþþe (talk) 18:38, 14 January 2017 (UTC)
- You could do pronunciation data like it was done for Ancient Greek (here's an example) and for spelling variants you might do something like:
# {{form of|early spelling of|droit|gloss=[[right]]|lang=fro}}
- While keeping all the pronunciation data at the main entry. Crom daba (talk) 02:12, 15 January 2017 (UTC)
- Is there no alternative to
{{form of}}here? That template should really only be used for one-off things, any kind of form-of message that could appear in many entries should have its own template. —CodeCat 02:14, 15 January 2017 (UTC)- Creating the equivalent template is left as an exercise for the reader. Crom daba (talk) 03:04, 15 January 2017 (UTC)
- FWIW, I'd consider the pronunciation /drwe/ as Middle French, not Late Old French. Also, Old French droit doesn't derive from Latin dirēctus, it derives from dirēctum. The reflex of dirēctus is OF droiz.
- For dreit vs. droit, you might consider a label
{{lb|early}}(or maybe{{lb|Early Old French}}), since it's more a dialectal than a spelling difference. Benwing2 (talk) 04:03, 15 January 2017 (UTC)- It doesn't matter what you consider it, Late Old French droit was pronounced /drwe/. Middle French had the same pronunciation, but all the relevant sound changes had already happened by 1350. And it doesn't really matter what it derives from, as droiz ended up as a homophone anyway. Not to mention both are just inflections, not separate words. ÞunoresWrǣþþe (talk) 18:56, 17 January 2017 (UTC)
- It's not a dialectal difference, one is a descendant of the other. Hwaet isn't a dialectal version of what (the same timespan separates both hwaet and what and dreit and droit). ÞunoresWrǣþþe (talk) 19:00, 17 January 2017 (UTC)
- It doesn't matter what you consider it, Late Old French droit was pronounced /drwe/. Middle French had the same pronunciation, but all the relevant sound changes had already happened by 1350. And it doesn't really matter what it derives from, as droiz ended up as a homophone anyway. Not to mention both are just inflections, not separate words. ÞunoresWrǣþþe (talk) 18:56, 17 January 2017 (UTC)
- Creating the equivalent template is left as an exercise for the reader. Crom daba (talk) 03:04, 15 January 2017 (UTC)
- Is there no alternative to
- You could do pronunciation data like it was done for Ancient Greek (here's an example) and for spelling variants you might do something like:
- That'd be great, they really are rather different, mainly since they cover almost a millenium (like Greek)!ÞunoresWrǣþþe (talk) 18:38, 14 January 2017 (UTC)
About "Glyph origin"
[edit]Some Chinese and Translingual entries have a "Glyph origin" section. Random example: 冫. A search for "glyph origin" (link) currently returns 6,071 results.
If people want to use that section, at least I'd like it to be mentioned in WT:EL. --Daniel Carrero (talk) 05:36, 15 January 2017 (UTC)
- I support adding it. —Μετάknowledgediscuss/deeds 00:59, 17 January 2017 (UTC)
- Does this not conceptually overlap with the Description header that e.g. explains why the biohazard symbol looks like it does? Equinox ◑ 14:32, 17 January 2017 (UTC)
- Actually, I think that "Glyph origin" overlaps with "Etymology", doesn't it? See the entry 水#Chinese (only the Chinese section has a "Glyph origin" subsection at the moment). It contains a table "Historical forms of the character 水". Should it be moved to "Etymology" in all entries? --Daniel Carrero (talk) 14:40, 17 January 2017 (UTC)
- Glyph Origin and Etymology are different. See ⿱成龍 for an example. —suzukaze (t・c) 22:26, 17 January 2017 (UTC)
I created Wiktionary:Votes/2017-02/Glyph origin. --Daniel Carrero (talk) 18:46, 6 February 2017 (UTC)
Morphological dictionary for Lithuanian or Serbo-Croatian?
[edit]Does anyone know of a good morphological dictionary for Lithuanian or Serbo-Croatian, comparable to Zaliznyak's book on Russian? (Grammaticheskii Slovar’ Russkogo Iazyka, aka Russian Grammar Dictionary) It should include in particular the accent patterns of words. I imagine such a thing might be written in Lithuanian or Serbo-Croatian, which isn't ideal as I don't speak either language, but I can potentially puzzle it out esp. with the help of a speaker. (I puzzled out Zaliznyak's book not really knowing Russian either, with the help of Google Translate.) Benwing2 (talk) 00:05, 17 January 2017 (UTC)
- The best monolingual dictionary for Lithuanian is, by far, this one. My favourite grammar of Standard Lithuanian is Mathiassen, but there are others that are good as well. Send me an email if you need further resources. —Μετάknowledgediscuss/deeds 00:59, 17 January 2017 (UTC)
- For Lithuanian you can also try these six dictionaries. --Vahag (talk) 06:19, 17 January 2017 (UTC)
Appendix for Russian patronymics
[edit]I think we need a special page for Russian patronymics. I didn't get around fixing notes in -ович, -евич, -ыч, etc. The rules and exceptions might need to go into a separate file, rather than describing them on each patronymic suffix entry. @Erutuon, thanks for your attempt, though.
Calling on whoever might be interested in collating the rules @Cinemantique, Benwing2, Wikitiki89, Erutuon, KoreanQuoter, Wanjuscha, Stephen G. Brown, CodeCat, Vahagn Petrosyan, Angr. Things to consider are formal patronymics (used in documents), colloquial forms and abbreviations, variants, irregular pronunciations (feminine -чна is consistently pronounced irregularly as -шна, as in Ильинична), stress patterns, declensions and categories, use of foreign names in the former USSR space and overseas, occasionally for expats living in Russia, naturalised migrants, usage. @Benwing2, does Zaliznyak cover this topic. @Cinemantique, it would be beneficial if the Russian Wiktionary cover this as well. --Anatoli T. (обсудить/вклад) 06:52, 17 January 2017 (UTC)
- I agree, but I don't have time to work on it right now. --WikiTiki89 15:39, 17 January 2017 (UTC)
- I don't think Zaliznyak covers this topic. I agree it would be great to have such an appendix. Benwing2 (talk) 08:47, 19 January 2017 (UTC)
Old Norse
[edit]How should we handle the evolution of "Old Norse"? For example, following the word Vreka from start to finish...
Proto-Germanic: IPA(key): /wrekɑnɑ̃/
Common West Scandinavian: IPA(key): /wrekɑ/
First Grammarian’s Icelandic: IPA(key): /wrεkɑ/ replace ε with ɛ, invalid IPA characters (ε)
Classical Old Icelandic: IPA(key): /vrεkɑ/ replace ε with ɛ, invalid IPA characters (ε)
Icelandic: IPA(key): /rɛka/
Common West Scandinavian, First Grammarian’s Icelandic and Classical Old Icelandic all count as Old Norse yet have very different pronunciations. How should this be represented in the entry for vreka? ÞunoresWrǣþþe (talk) 21:08, 17 January 2017 (UTC)
- @ÞunoresWrǣþþe: Are you making and Old Norse pronunciation module? Also, what are your sources for these pronunciations? —JohnC5 21:25, 17 January 2017 (UTC)
- No, I'm asking how we should differentiate the different pronunciations the word had in Old Norse. My sources are Old Icelandic: Its Structures and Development by Hreinn Benediktsson, The First Grammatical Treatise: The earliest Germanic Phonology by Einar Haugen, The Nordic Languages, An International Handbook on the History of the North Germanic Languages by Oskar Bandle and primary sources. ÞunoresWrǣþþe (talk) 22:51, 17 January 2017 (UTC)
- You can use
{{a}}to specify a specific accent. DTLHS (talk) 22:52, 17 January 2017 (UTC)- It's not an accent, they are separate, descendant languages. "Old Norse" is a blanket term that frankly shouldn't really be used given how many sound changes occurred in it. ÞunoresWrǣþþe (talk) 23:06, 17 January 2017 (UTC)
- This problem exists for all ancient languages. Ancient Greek, for example, covers 2000+ years. They've handled the changing pronunciations quite well, I think, for that language. Benwing2 (talk) 23:13, 17 January 2017 (UTC)
- Some can understandably be exempted, like Old English. The only sound changes in the seven century span that I can think of are syncope towards the end, and unstressed e's becoming schwas and eventually being dropped. For something like wrekɑ > vrεkɑ, some sort of note of the different pronunciations seems like it would be useful. ÞunoresWrǣþþe (talk) 23:21, 17 January 2017 (UTC)
- Several points: phonological change is not the only thing that determines whether two lects get considered separate languages. Indeed, many dialects of modern English are as far apart in pronunciation as these historical periods of Old Norse, but they are still English. There is also disagreement about how sequences such as ⟨hv⟩, ⟨hr⟩, ⟨hl⟩, ⟨hn⟩, and ⟨-r⟩ would have been pronounced at different times. —JohnC5 23:29, 17 January 2017 (UTC)
- Some can understandably be exempted, like Old English. The only sound changes in the seven century span that I can think of are syncope towards the end, and unstressed e's becoming schwas and eventually being dropped. For something like wrekɑ > vrεkɑ, some sort of note of the different pronunciations seems like it would be useful. ÞunoresWrǣþþe (talk) 23:21, 17 January 2017 (UTC)
- This problem exists for all ancient languages. Ancient Greek, for example, covers 2000+ years. They've handled the changing pronunciations quite well, I think, for that language. Benwing2 (talk) 23:13, 17 January 2017 (UTC)
- It's not an accent, they are separate, descendant languages. "Old Norse" is a blanket term that frankly shouldn't really be used given how many sound changes occurred in it. ÞunoresWrǣþþe (talk) 23:06, 17 January 2017 (UTC)
- You can use
- No, I'm asking how we should differentiate the different pronunciations the word had in Old Norse. My sources are Old Icelandic: Its Structures and Development by Hreinn Benediktsson, The First Grammatical Treatise: The earliest Germanic Phonology by Einar Haugen, The Nordic Languages, An International Handbook on the History of the North Germanic Languages by Oskar Bandle and primary sources. ÞunoresWrǣþþe (talk) 22:51, 17 January 2017 (UTC)
- Are you actually implying that PGM /e/ was [e] and lowered to [ɛ]? Korn [kʰũːɘ̃n] (talk) 23:58, 17 January 2017 (UTC)
- Oh lol, I didn't even notice that! —JohnC5 00:25, 18 January 2017 (UTC)
- @ÞunoresWrǣþþe: Why not just add all three of those Old Norse pronunciations (Common West Scandinavian, First Grammarian’s Icelandic, and Classical Old Icelandic) to the Old Norse entry in question? — I.S.M.E.T.A. 14:42, 15 February 2017 (UTC)
Policy proposal for LDLs.
[edit]In the light of some recent events, and since everyone expects me to do it for some reason, I'd like to toss something into the ring concerning uncodified languages which do not have an extensive written coverage and a great variety of written forms and thus put us before an issue when it comes to inclusion. We could make at least two dozen entries for some words, we know some words exist in some languages but they are never used in a CFI way, only recorded in professional works' IPA. The idea I want to put forward is to organise entries of such languages according to their last standardised form, even if it is only standardised by the scientific community. For example the regional nordic varieties would become standardised around Old Norse normalisation. To give an example from a field I actually understand: Normalised Middle Low German has fîf (5), modern forms are fif, fief, fiv, fiev, fiw, fiew, fiwe, five etc. pp. As long as we can reasonably decypher the origin of a word, we would make a hub entry based on the normalised form (fîf after Middle LG) and everything else links to it as an alternative form. Do you think this is feasible? Do you see issues? Should we have it in main entries or appendix? What are your thoughts? Korn [kʰũːɘ̃n] (talk) 11:03, 18 January 2017 (UTC)
- @Korn: This is an excellent question and one that I don't think is really answered outright in Wiktionary:Criteria for inclusion. We are to include terms that one would "run across" but for dead languages, no one would "run across" anything except in print. Similarly, for a living language which is generally not documented (or at least, generally not documented with print, a la American Sign Language), one could definitely "run across" all manner of words which simply aren't encoded in written language. So there are verifiable variants of words which someone would never encounter unless he were reading 13th-century Scottish land transactions and there are words which are used on a daily basis by communities which have used a language for thousands of years. It's not really clear to me what exactly Wiktionary is attempting to include. If it's all terms one would run across then documenting oral/sign-only languages is virtually impossible. If it's all written encodings of terms that one can verify in print or digital media, then we will inevitably have huge numbers of variant spellings of the same term which will be very difficult to harmonize. If we want to do both, then we have both problems. As someone who edits here regularly but doesn't really get into the nuts and bolts of the site, this has confused me for years. —Justin (koavf)❤T☮C☺M☯ 15:34, 18 January 2017 (UTC)
- Yes, we have many alternative spellings, and for extinct or minority languages, it is common practice to choose a single orthographic standard to lemmatise. Also, we do cover sign languages. —Μετάknowledgediscuss/deeds 15:48, 18 January 2017 (UTC)
- @Metaknowledge: Either I was unclear or your response was a little hasty: I realize that we cover sign languages. The point that I was making is that there are very common terms in many languages (most of them) which are difficult if not impossible to include here on a practical and technical level. There are speakers of languages which have no script at all, so that language certainly does exist and if you were in that community, you would run across myriad terms which we cannot include here since there is no way to write that language. (Or to put it alternately, there are many ways one could write it but none of those has been adopted by that community.) The same is true of sign languages which are only documented in audio/visual media and those communities do not use the methods for written notation that a few specialists have devised. They could—they simply choose to not. Prioritizing one form is fine but it does leave the possibility that the content at "color" and "colour" will drift and change over time in ways that we wouldn't want—these two spellings refer to the same word and concept. (We definitely would want different quotations/attestations but we would not want different definitions or translations. The etymologies would be slightly different, of course.) And of course, prioritizing one form over another is compounded by languages which use or have used different scripts: the Serbian version of Bosnian/Croatian/Montenegrin/Serbian uses Cyrillic and Latin alphabets. Kurdish variations use Arabic-based and Latin-based scripts, plus they formerly used Cyrillic-based scripts. Lithuanian was briefly written with Cyrillic characters, so there are Cyrillic versions of "name" or "house" but not for "computer". So the two difficulties I was trying to explain above are that 1.) there are many terms which we cannot include in principle as this is a written dictionary but those terms presumably could or should be included and 2.) there are many variant forms (spellings or transliterations) which we have to maintain to keep from forking into separate definitions. These two problems are pretty fundamental to the project but it's not clear to me what the solutions are. (I recall discussion on the latter at one of the discussion forums from last year). There may not be any one silver bullet solution—I suspect there's not—but as someone who uses this site on a daily basis for years, I don't know what the community has decided about these two problems. —Justin (koavf)❤T☮C☺M☯ 16:05, 18 January 2017 (UTC)
- I agree that forking should be minimised; we make exceptions for issues like American vs Commonwealth or Serbian vs Croatian, but generally we choose one standard or script to lemmatise at. I doubt they've been created, but any Cyrillic Lithuanian that meets CFI should be added as an alternative spelling with an appropriate label, just like we have Afrikaans entries in Arabic script, etc. —Μετάknowledgediscuss/deeds 16:10, 18 January 2017 (UTC)
- Why are there exceptions? Korn [kʰũːɘ̃n] (talk) 16:48, 18 January 2017 (UTC)
- For political reasons. Crom daba (talk) 17:35, 18 January 2017 (UTC)
-
- organise entries of such languages according to their last standardised form (…) For example the regional nordic varieties would become standardised around Old Norse normalisation
- Is this particular example somewhat off-center, in that modern Nordic regional varieties generally aren't very close to Old Norse? Do I read you right that you'd want to eliminate separate Elfdalian or Jamtish entries, and replace them with pronunciation footnotes in Old Norse entries? This sounds like a poor idea, and also one that does not particularly generalize: most of the time unwritten language varieties simply have no earlier written standard to fall back on, and in many cases where there it, it would take us impracticably far back (e.g. with modern Aramaic, modern West Iranian, some modern Indo-Aryan, or even some modern Romance varieties, the closest written direct ancestors are going to be all the way back in antiquity). But maybe I'm misunderstanding.
- In any case, I agree with the main observation: many LDLs are often going to be essentially un-CFI, if not unverifiable from uses altogether. I wonder if a first step should be to divide LDLs into a couple subcategories. The following seem reasonably distinguishable:
- living languages with an established literary tradition but poor online representation (e.g. Mon, Javanese)
- living languages with at most a nascent, unstandardized literary tradition (e.g. Elfdalian, Karelian, Tuvan, Tulu, Navajo)
- extinct/liturgical languages with a reasonably-sized corpus (e.g. Ancient Greek, Akkadian, Coptic, Old Tupi)
- extinct languages with only fragmentary records known (e.g. Oscan, Phrygian, Crimean Gothic, Old East Japanese)
- extinct unwritten languages documented only in linguistic works (e.g. Mator, Sireniki, Yurok, Mbabaram)
- I expect #2 will be the largest category by number of languages (and, therefore, potential entries), and the default LDL policies should probably be fine-tuned for them. Non-standard dialects could probably also follow the same guidelines. The majority of current LDL entries are however probably from #1 and #3, which may require their own separate CFI standards. Lastly, I am not convinced if #4 and especially #5 should be covered in mainspace at all. --Tropylium (talk) 16:25, 20 January 2017 (UTC)
- Sorry, to clarify: The proposal specifically was that out default approach be that we devise our own normalisations based on the normalisation/standard of the closest ancestor, even if a divergent but non-exhaustive (doesn't cover enough spoken language) and/or chaotic (differs somewhat strongly from author to author) written form exists. Korn [kʰũːɘ̃n] (talk) 22:00, 20 January 2017 (UTC)
- I'm most interested in Middle English and Scots, with respect to this issue. Both have decent sized corpuses, but huge variability in spelling, including in the case of Middle English many works published in spellings that have been normalized towards modern English. Having only normalized entries with Middle English isn't going to help the reader much.--Prosfilaes (talk) 21:26, 22 January 2017 (UTC)
- Nobody said 'only'. They become the entry, everything else links back to it. To avoid having fifteen entries or multiple discussions which form to consider the entry and which an alternative form. Korn [kʰũːɘ̃n] (talk) 22:05, 22 January 2017 (UTC)
@I'm so meta even this acronym I guess this qualifies as 'gets going'. Korn [kʰũːɘ̃n] (talk) 11:39, 23 January 2017 (UTC)
- @Korn: Thanks the the ping. I shall mull over this a bit, and then contribute. — I.S.M.E.T.A. 12:58, 15 February 2017 (UTC)
Getting rid of the idiomatic tag
[edit]In my opinion, it doesn't carry any useful information whatsoever, and in many -if not all- instances could be best replaced by the figuratively tag; in fact, that's what I've been doing, and I'm sure nobody would break a sweat if I kept doing that silently. What do you think? --Barytonesis (talk) 19:57, 18 January 2017 (UTC)
- Support, though it can't always be replaced with "figuratively". Figuratively requires a contrasting literal meaning, but we don't include literal meanings because they are SoP. Therefore, every term consisting of multiple words that is includable is implicitly not literal. I am not convinced that the "figuratively" label is useful for single-word terms either. For me, there's no literal and figurative senses of a word, there's just senses. —CodeCat 20:12, 18 January 2017 (UTC)
- Sometimes it seems to have been used where colloquial would be more appropriate, e.g. bucket down. Equinox ◑ 20:14, 18 January 2017 (UTC)
- Ofttimes, colloquial is used where informal would seem better. I've thought that colloquial indicated a set of situations, not a register. DCDuring TALK 20:43, 18 January 2017 (UTC)
- Might be nice to create a style guide that connects each of the many labels to how we, collectively, use them and expect them to be used. - TheDaveRoss 21:38, 18 January 2017 (UTC)
- Ofttimes, colloquial is used where informal would seem better. I've thought that colloquial indicated a set of situations, not a register. DCDuring TALK 20:43, 18 January 2017 (UTC)
- I support removing it in general, but I think it should be done carefully in a way that ensures that if some tag is needed, then a good replacement is found. --WikiTiki89 21:56, 18 January 2017 (UTC)
- What about cases in which a word can have a certain meaning in a (limited) number of set phrases but only in them? I'd use idiomatically in such cases, would this also be removed? Crom daba (talk) 00:46, 19 January 2017 (UTC)
- I would label that "in idioms". --WikiTiki89 15:39, 19 January 2017 (UTC)
- I think there's at least some usefulness to the idiomatic tag. For one thing, we have the
{{&lit}}template that opposes it. For another, for phrasal verbs like get down or throw up, some of the definitions given follow logically from the sum of their parts (even if it's not completely obvious a priori that the phrases can be used in that fashion) and others certainly don't (e.g. get down meanings #1, 3, 4, 6, 8, 9 are at least partially non-idiomatic, whereas #5 and 7 are certainly idiomatic. Similarly, throw up meanings #1, 4, 5 are more or less non-idiomatic, where #2 (to "vomit") is almost protypically idiomatic (and I would dispute that it's colloquial, I think it's actually quite neutral in register). Benwing2 (talk) 03:35, 19 January 2017 (UTC)
- Usually it can and should just be removed. - -sche (discuss) 11:02, 20 January 2017 (UTC)
Possibly useful site for Early Modern English attestation
[edit]See here This site is a part of Zooniverse which has some people-powered research which is a little tangential to what we do here (somewhat similar to v:) and this project attempts to transcribe all manner of works from the time of Shakespeare to provide context to his plays. It could also be useful for some of us looking for spellings or older instances of words. —Justin (koavf)❤T☮C☺M☯ 21:19, 18 January 2017 (UTC)
- @Koavf: Lovely! Thanks for posting this link. — I.S.M.E.T.A. 13:22, 15 February 2017 (UTC)
Arabic consonant patterns
[edit]Most languages have suffixes or prefixes, which are easy to write entries on, but Arabic has consonant templates. Perhaps we could add a new POS type under the category of morpheme (alongside prefix, suffix, circumfix, root, and so on): perhaps Pattern. Then, using the root traditionally used to describe morphological forms, ف ع ل (f-ʕ-l) (and its variations), entries could be created for patterns such as فَعَلَ (faʕala), فَعِلَ (faʕila), فَعِيل (faʕīl), فَاعِل (fāʕil), فَعَائِل (faʕāʔil), فَعَائِيل (faʕāʔīl), فَعَى (faʕā), فَعَا (faʕā), فَاعَ (fāʕa), فَعْلَقَ (faʕlaqa), and their various meanings and alternative forms could be described, in much the same way that the various meanings and variations of a suffix like -y are described. As with prefixes and suffixes, there would be a main category, Category:Arabic patterns, and subcategories like Category:Arabic noun-forming patterns, Category:Arabic verb-forming patterns, Category:Arabic diminutive patterns, and so on.
The alternative, I suppose, would be an appendix that lists these patterns and defines them. But I think it would be unnecessarily biased against nonconcatenative morphology to not have the patterns described in the main namespace in the same way as concatenative morphemes such as prefix and suffix are.
I wonder, has this idea been proposed before? @CodeCat, Atitarev, Wikitiki89, Mahmudmasri, Benwing, ZxxZxxZ, any thoughts? — Eru·tuon 23:17, 18 January 2017 (UTC)
- These are in Hebrew too (binyan), and maybe other Semitic languages. Equinox ◑ 23:20, 18 January 2017 (UTC)
- See w:Transfix. —CodeCat 23:47, 18 January 2017 (UTC)
- So I guess the question is, shall we use transfix or pattern for this morphological concept? Pattern is a translation of وَزْن (wazn), I think, so it would be more traditional. — Eru·tuon 03:43, 19 January 2017 (UTC)
- I'd rather use transfix, as it's the linguistic term, and also more distinctive than "pattern". It also fits better with other kinds of -fixes. —CodeCat 14:11, 19 January 2017 (UTC)
- @CodeCat: In all the linguistic literature I've read about Semitic languages, I have never encountered the word "transfix". They usually either use the word "pattern" or a borrowing from one of the languages, such as "wazn" or "mishqal". Sometimes other words like "mold" are used. @Erutuon: "Pattern" is not a translation of وَزْن (wazn), but simply an English description of the phenomenon. A translation of وَزْن (wazn) would have been "weight" (the Hebrew מִשְׁקָל (mishkál) is probably a translation of وَزْن (wazn)). --WikiTiki89 15:53, 19 January 2017 (UTC)
- Thanks for tagging me. I would rather go for pattern, but it appears that transfix had already been chosen. --Mahmudmasri (talk) 19:06, 19 January 2017 (UTC)
- Category:Arabic patterns is a really bad name. It's far too ambiguous a term, "pattern" can mean many things. We should choose a name that is clear. —CodeCat 19:09, 19 January 2017 (UTC)
- It's not ambiguous if it's clearly explained on the page. You're the only one who supports "transfix" and you don't even work with these languages. We already have Category:Hebrew terms by pattern, if you want to see how it could look. --WikiTiki89 19:15, 19 January 2017 (UTC)
- Category:Arabic patterns is a really bad name. It's far too ambiguous a term, "pattern" can mean many things. We should choose a name that is clear. —CodeCat 19:09, 19 January 2017 (UTC)
- Thanks for tagging me. I would rather go for pattern, but it appears that transfix had already been chosen. --Mahmudmasri (talk) 19:06, 19 January 2017 (UTC)
- @CodeCat: In all the linguistic literature I've read about Semitic languages, I have never encountered the word "transfix". They usually either use the word "pattern" or a borrowing from one of the languages, such as "wazn" or "mishqal". Sometimes other words like "mold" are used. @Erutuon: "Pattern" is not a translation of وَزْن (wazn), but simply an English description of the phenomenon. A translation of وَزْن (wazn) would have been "weight" (the Hebrew מִשְׁקָל (mishkál) is probably a translation of وَزْن (wazn)). --WikiTiki89 15:53, 19 January 2017 (UTC)
- I'd rather use transfix, as it's the linguistic term, and also more distinctive than "pattern". It also fits better with other kinds of -fixes. —CodeCat 14:11, 19 January 2017 (UTC)
- So I guess the question is, shall we use transfix or pattern for this morphological concept? Pattern is a translation of وَزْن (wazn), I think, so it would be more traditional. — Eru·tuon 03:43, 19 January 2017 (UTC)
- We are already (to some extent) doing this for Hebrew. See the root and pattern links (and categories) at the entry מלכה. I've been considering doing this for Arabic as well. --WikiTiki89 23:49, 18 January 2017 (UTC)
- Lexical content shouldn't be in appendixes, I think. Appendixes can be used to clarify a topic or give an overview of forms, but the actual forms should still have real entries. —CodeCat 23:52, 18 January 2017 (UTC)
- But the patterns are often only quasi-lexical. Sometimes they have well-defined meanings, other times they are just happenstance. --WikiTiki89 00:07, 19 January 2017 (UTC)
- Perhaps we could establish official criteria to distinguish happenstance from lexical patterns. Perhaps we could classify them as lexical if an identifiable meaning for the pattern can be discerned in at least three terms using the pattern. This criterion would easily apply to the patterns I mentioned above. But the pattern فِعَال (fiʕāl) of كِتَاب (kitāb) might not, so it might have to go in an appendix. (On the other hand, another use of the pattern, for an adjectival broken plural, as in جِمَال (jimāl), might qualify as lexical.) — Eru·tuon 03:43, 19 January 2017 (UTC)
- @Erutuon: I think it would be confusing to have some patterns in one place and others in another place. It would be better to have them either all in the main namespace or all in the appendix. Another reason I don't like the idea of having them in the main namespace is because they contain placeholder consonants that are not really part of the morpheme. That gets especially confusing if it coincides with an actual word. --WikiTiki89 15:53, 19 January 2017 (UTC)
- Perhaps we could establish official criteria to distinguish happenstance from lexical patterns. Perhaps we could classify them as lexical if an identifiable meaning for the pattern can be discerned in at least three terms using the pattern. This criterion would easily apply to the patterns I mentioned above. But the pattern فِعَال (fiʕāl) of كِتَاب (kitāb) might not, so it might have to go in an appendix. (On the other hand, another use of the pattern, for an adjectival broken plural, as in جِمَال (jimāl), might qualify as lexical.) — Eru·tuon 03:43, 19 January 2017 (UTC)
- But the patterns are often only quasi-lexical. Sometimes they have well-defined meanings, other times they are just happenstance. --WikiTiki89 00:07, 19 January 2017 (UTC)
- Lexical content shouldn't be in appendixes, I think. Appendixes can be used to clarify a topic or give an overview of forms, but the actual forms should still have real entries. —CodeCat 23:52, 18 January 2017 (UTC)
- I support the idea but this is already happening (Erutuon must be aware of this, judging by the edits): Category:Arabic_roots. Ideally, all Arabic terms, which have
{{ar-root}}in the Etymology sections, should be categorised by the root letters for the ease of locating them. E.g تَكْفِير (takfīr) is formed from the root letters{{ar-root|ك|ف|ر}}(k-f-r) and should be searchable by k-f-r, even if it starts with "t" (ت) if searched alphabetically. --Anatoli T. (обсудить/вклад) 00:03, 19 January 2017 (UTC)- In Arabic, we are doing it for roots, but not for patterns. --WikiTiki89 00:07, 19 January 2017 (UTC)
- Ah, I see, patterns. Yes, I support this as well. Loanwords, if they are not formed by using a pattern, should somehow be excluded. I think it's better to use romanised names for categories, e.g. Category:Arabic fāʿil pattern, which may belong to other pattern groups. --Anatoli T. (обсудить/вклад) 00:11, 19 January 2017 (UTC)
- It should be mentioned that for verbs it's possible to categorize any verb with a conjugation template (which is essentially all of them) by root already --
{{ar-conj}}automatically computes the root of a verb as part of its operation, and AFAIK there are no loanword verbs in Arabic. Benwing2 (talk) 03:22, 19 January 2017 (UTC)- برج says it was borrowed, or should the noun and verb go in different etymology sections? (also has a descendant from the same term from which it was supposedly borrowed). DTLHS (talk) 03:33, 19 January 2017 (UTC)
- The verb appears unrelated to the noun and IMO should be in a different etym seciton. OTOH now that I think of it there are clearly verbs that are indirectly borrowed, e.g. تَفَلْسَفَ (tafalsafa, “to philosophize”), although in this case it's formed from a borrowed noun and it could still be argued that it was formed by extracting a root f-l-s-f and applying a verbal pattern to it, and the root thereby acquired a meaning "philosophy". Hebrew similarly has לסבסד (lesabsed, “to subsidize”) where the same thing could be said, I think. Benwing2 (talk) 03:40, 19 January 2017 (UTC)
- @Benwing2: Yes, I think the best way of looking at it is that the root was extracted from the noun and now exists on its own. The decision for Hebrew was that categorization by root is synchronic, so it doesn't matter if the word came from the root or the root came from the word or whatever else. --WikiTiki89 15:53, 19 January 2017 (UTC)
- The verb appears unrelated to the noun and IMO should be in a different etym seciton. OTOH now that I think of it there are clearly verbs that are indirectly borrowed, e.g. تَفَلْسَفَ (tafalsafa, “to philosophize”), although in this case it's formed from a borrowed noun and it could still be argued that it was formed by extracting a root f-l-s-f and applying a verbal pattern to it, and the root thereby acquired a meaning "philosophy". Hebrew similarly has לסבסד (lesabsed, “to subsidize”) where the same thing could be said, I think. Benwing2 (talk) 03:40, 19 January 2017 (UTC)
- برج says it was borrowed, or should the noun and verb go in different etymology sections? (also has a descendant from the same term from which it was supposedly borrowed). DTLHS (talk) 03:33, 19 January 2017 (UTC)
- It should be mentioned that for verbs it's possible to categorize any verb with a conjugation template (which is essentially all of them) by root already --
- Ah, I see, patterns. Yes, I support this as well. Loanwords, if they are not formed by using a pattern, should somehow be excluded. I think it's better to use romanised names for categories, e.g. Category:Arabic fāʿil pattern, which may belong to other pattern groups. --Anatoli T. (обсудить/вклад) 00:11, 19 January 2017 (UTC)
- In Arabic, we are doing it for roots, but not for patterns. --WikiTiki89 00:07, 19 January 2017 (UTC)
- @Erutuon: Am I correct in interpreting a term's pattern as its discontinuous series of vowels which dovetails with its consonantal root? — I.S.M.E.T.A. 13:15, 15 February 2017 (UTC)
- @I'm so meta even this acronym: Close. A pattern can also contain additional consonants that are not part of the root. --WikiTiki89 16:48, 15 February 2017 (UTC)
- @Wikitiki89: OK, thanks for the clarification. Another issue: Do there exist spacing equivalents of the combining harakat? — I.S.M.E.T.A. 08:20, 6 March 2017 (UTC)
- @I'm so meta even this acronym: I searched UnicodeLookup.com, and there are "isolated forms" (of fatḥa, U+FE76, of ḍamma, U+FE78, of kasra, U+FE7A). However, I typically use the combining character above the taṭwīl (U+640) when mentioning the vowel diacritics. Perhaps this is incorrect. — Eru·tuon 08:31, 6 March 2017 (UTC)
- @Wikitiki89: OK, thanks for the clarification. Another issue: Do there exist spacing equivalents of the combining harakat? — I.S.M.E.T.A. 08:20, 6 March 2017 (UTC)
- @Erutuon: I've seen ⟨ـ⟩ (U+0640 ARABIC TATWEEL) used in the same way on Wikipedia; it makes sense to me, from reading w:Kashida, to do so, since the tatweel (AFAICT) is a purely typographical item, and carries no phonological information. I asked about spacing forms to gauge the practicality of describing patterns without using the ف ع ل (f-ʕ-l) base; would entries like ﹶ ﹶ ﹶ (-a-a-a) [for فَعَلَ (faʕala)], ﹶ ﹺ ﹶ (-a-i-a) [for فَعِلَ (faʕila)], and ﹶ ﹾ ﹶ ﹶ (-a--aqa) [for فَعْلَقَ (faʕlaqa)] be possible and/or desirable? — I.S.M.E.T.A. 08:59, 6 March 2017 (UTC)
- @I'm so meta even this acronym: These are all possible, but would look very confusing. For example, the pattern تَفْعِيل (tafʕīl) would look like تَ ْ ِي (ta--ī-) or تَـْـِيـ (ta--ī-), which is ugly and confusing. Why not stick with what nearly all grammarians, lexicographers, and linguists of Arabic do? --WikiTiki89 17:08, 6 March 2017 (UTC)
- @I'm so meta even this acronym: I agree with @Wikitiki89 that that way of showing the patterns would be confusing. It is difficult to look at the series of Arabic diacritics and figure out where the root consonants are supposed to go, or how many there are, since the consonants are absent. For instance, to someone uninitiated in Arabic spelling, ﹶ ﹶ ﹶ could be أَفَعَل (ʔafaʕal) as easily as فَعَلَ (faʕala). (It's unambiguous only if you know that an initial a has to be above a hamza or glottal stop, and that the hamza would therefore be in the spelling of the pattern.) I suppose the use of ف ع ل (f ʕ l) and ف ع ل ق (f ʕ l q) to represent three- and four-letter roots in patterns requires some initiation, but it is at least clear where the consonants go, because they are explicitly written in the Arabic spelling. (A correction: ﹶ ﹾ ﹶ ﹶ should be transliterated -a--a-a with four hyphens, because it represents a four-letter root.) — Eru·tuon 21:30, 6 March 2017 (UTC)
- @Erutuon: I've seen ⟨ـ⟩ (U+0640 ARABIC TATWEEL) used in the same way on Wikipedia; it makes sense to me, from reading w:Kashida, to do so, since the tatweel (AFAICT) is a purely typographical item, and carries no phonological information. I asked about spacing forms to gauge the practicality of describing patterns without using the ف ع ل (f-ʕ-l) base; would entries like ﹶ ﹶ ﹶ (-a-a-a) [for فَعَلَ (faʕala)], ﹶ ﹺ ﹶ (-a-i-a) [for فَعِلَ (faʕila)], and ﹶ ﹾ ﹶ ﹶ (-a--aqa) [for فَعْلَقَ (faʕlaqa)] be possible and/or desirable? — I.S.M.E.T.A. 08:59, 6 March 2017 (UTC)
On the subject of whether patterns should be placed in the Appendix namespace: I think that if they are, then roots should probably be as well. The existence of roots is dependent on the existence of patterns, so they should be there together. And what @Wikitiki89 said about patterns is also true about roots: they are often just happenstance. Many words that appear to be from a root have a meaning that is unrelated to the meaning of the more regularly derived terms from the root. I encountered this a lot when creating Arabic root entries. — Eru·tuon 21:35, 6 March 2017 (UTC)
- @Wikitiki89: I pretty much am in favour of “stick[ing] with what nearly all grammarians, lexicographers, and linguists of Arabic do”, but I want to investigate alternatives, just in case. Here are two ways of presenting the etymology of تَفْعِيل (tafʕīl): without the tatweed and with it (I made a mistake: the pattern's transliteration is meant to be ⟨ta-∅-ī-⟩ in both cases); I find the equation with the tatweed:
ف ع ل (f-ʿ-l) + تَـْـِيـ (ta-∅-ī-) = تَفْعِيل (tafʕīl)
more intuitive. Like CodeCat, I found the presence of the ف ع ل (f-ʕ-l) base consonants in the (largely vocalic) pattern confusing initially; however, if the base never changes, that confusion soon abates. Still, is there some way of having both presentations? — I.S.M.E.T.A. 22:20, 6 March 2017 (UTC)- It would probably be possible to convert one version to the other using Lua. — Eru·tuon 22:49, 6 March 2017 (UTC)
- @I'm so meta even this acronym: I think we can make the patterns more easy to understand by displaying them in a table. I made a Lua function that shows what I mean; see here. — Eru·tuon 01:35, 7 March 2017 (UTC)
- @Wikitiki89: I pretty much am in favour of “stick[ing] with what nearly all grammarians, lexicographers, and linguists of Arabic do”, but I want to investigate alternatives, just in case. Here are two ways of presenting the etymology of تَفْعِيل (tafʕīl): without the tatweed and with it (I made a mistake: the pattern's transliteration is meant to be ⟨ta-∅-ī-⟩ in both cases); I find the equation with the tatweed:
- @Erutuon: Ah, I see what you mean. Thanks for that. It might be clearer, however, if the component phones of the roots and patterns were ordered from right to left, per the directionality of the Arabic script, rather than from left to right. Is that institutable? — I.S.M.E.T.A. 16:11, 1 April 2017 (UTC)
I've now created {{transfix}}, which works like the other morphology templates. It has a corresponding category template {{transfixcat}}. —CodeCat 15:00, 19 January 2017 (UTC)
Hi, @Erutuon, @Wikitiki89, @CodeCat and everyone else. It has been nearly a year. Not even a single entry uses the transfix template. I think we can just cancel it? --Octahedron80 (talk) 04:37, 6 December 2017 (UTC)
- I agree. --WikiTiki89 15:50, 6 December 2017 (UTC)
- CodeCat is @Rua now. --Rerum scriptor (talk) 15:59, 6 December 2017 (UTC)
- It would help if there were some examples. From the documentation, I haven't a clue how one is supposed to use it. Some examples would help. --RichardW57 (talk) 16:42, 27 July 2020 (UTC)
- @Erutuon: Now after four years we apparently have bright moments and leisure to test all, thanks to the CCP virus, I have now looked how to use
{{transfix}}after one had suggested a disfix template. Richard is on something. While the documentation now shows the syntax, it is unclear what to supply to the third parameter (or for what the second one is used so far, perhaps to replace{{ar-root}}, so people do not need to write unnecessary fake derivations “from the root” to only categorize and link a root, although linking it is still needed. Either{{transfix}}takes over the role or we switch to a{{HE root}}style template to complement{{transfix}}in Arabic entries). So if I want to categorize فُقَاع (fuqāʕ) and فُقَّاع (fuqqāʕ) I do what?{{transfix|ar|ف ق ع|فُعَال}}for the first? It links to فعال since the diacritics are stripped, should we create the dummy entries فُعَال (fuʕāl), فُعَّال (fuʕʕāl), فِعَال (fiʕāl), فَعَال (faʕāl), فَعَّال (faʕʕāl), to describe the transfixes? Is this what you mean above? (Or ك (k) ل (l) م (m) ن (n) alternatively, from كَلِمَة (kalima, “word”), probably not). The categorization is a fail, Category:Arabic words transfixed with فعال, except I distinguish the patterns by id, as the diacritics are stripped, but the template does not accept IDs (|id=ailmentwould be one – the pattern of فُقَاع (fuqāʕ) is well-known to form names of ailments –, not thought true by @Rua I guess). Similarly we cannot use something like ـُــَاـ, as the kashida is stripped, and there was a talk already somewhere where it was rightly observed that this kashida use is inconspicuous for the eyes. Does it even makes sense in general to strip diacritics in affix templates? Fay Freak (talk) 16:14, 18 August 2020 (UTC)
- @Erutuon: Now after four years we apparently have bright moments and leisure to test all, thanks to the CCP virus, I have now looked how to use
Per-sense genders
[edit]We currently have mechanisms to indicate the genders of nouns in the headword, and we have the ability to indicate multiple genders. However, there are occasionally multi-gender nouns that have the same etymology and thus are one word (i.e. one "Noun" header and headword, one inflection table) but for which the genders are different for different senses. We have no method of showing this, currently. Context labels don't seem appropriate, because they set a context in which a certain sense applies, while this is the opposite: rather than "when feminine, the noun means X", this is "when the noun means X, it is feminine", cause and effect are the other way around. So how should we deal with it? —CodeCat 15:18, 19 January 2017 (UTC)
- We had this conversation last year; see this discussion. The upshot is that multiple noun headers works fine in most cases. —Μετάknowledgediscuss/deeds 15:42, 19 January 2017 (UTC)
- I don't find that solution satisfactory at all, so I'd like to ask for a better one. —CodeCat 16:24, 19 January 2017 (UTC)
- @CodeCat: I agree that that is not a satisfactory solution. I tend to use context labels, which is the method you initially criticised, because I know of no better solution/presentation. — I.S.M.E.T.A. 13:27, 15 February 2017 (UTC)
- How about two noun sections? I don't have any example, but when in German die Leiter and der Leiter would have the same etymology there could be two Noun sections (===Noun=== or ====Noun=====) and two headers. Also in German it would be a mess to use one header for both genders like {{head|de|noun|g=m|g2=f|....}} as the word declines differently based on the gender (der Leiter, gen. des Leiters, pl. die Leiter; die Leiter, gen. der Leiter, pl. die Leitern). -80.133.114.49 15:47, 22 January 2017 (UTC)
User keeps adding nonstandard Dutch diminutives
[edit]The IP user that speaks in gibberish, User:62.235.174.135, keeps adding nonstandard dialectal diminutives to entries. I've asked them to stop, but just received more gibberish in response and they've continued to do it. Can someone make the point more clear, please? —CodeCat 13:21, 22 January 2017 (UTC)
- It's good that they add some Belgian Dutch coverage, of which we don't have a lot on Wiktionary, and for that reason I've been working a bit with this anon to improve the entries they created and I don't want to be too harsh about some mistakes they make while editing. But rules are still rules, and their writing style (which is due to a strain injury which makes it difficult for them to type, so they use a shorthand which can look like gibberish) is just a tad too abbreviated to be easily understood, which can be annoying. — Kleio (t · c) 15:34, 22 January 2017 (UTC)
- What's nonstandard and dialectal about snottebelleke, mantelzorgerke?
- -ke, -ken, -tje mention a Dutch suffix -ke without saying anything like nonstandard or dialectal. Let's assume it is dialectal. Is it used in regular Dutch or just in dialects or dialects of other languages like Dutch Low German? Compare for example with German -li. In usual German it's uncommon, in dialectal German (Alemannic German, not regular German) it is used, and in Swiss German (regional German but still regular German) it's sometimes used as well. Even Duden has an entry for example for Hörnli (www.duden.de/rechtschreibung/Hoernli). If Hörnli would have the meaning little horn in (Swiss) German, it would be a regional diminutive of Horn, but would still be regular German and not just dialectal. The problem then would be wiktionary's habit of adding dimutives. Diminutives and gendered forms usually are derived terms like Hörnlein is Horn + suffix -lein (and umlaut), Lehrererin is Lehrer + suffix -in. But when adding some derived terms like diminutives in the header, I can't see any reason to exclude regional, e.g. Swiss German, diminutives. Also why are diminutives added in headers but no adjectives like friend (... adjective friendly) or abstract nouns like green (.... abstract greenness) or collectives like Brüder (... collective Gebrüder)? It should make more sense to mention derived and related terms (diminutives, adjectives, collectives) only as derived and related terms respectively and not in headers.
- As for Horn and Hörnli: Duden only has the figurative meaning croissant (compare with Hörnchen) for Hörnli, and I haven't seen Hörnli meaning little horn in (Swiss) German. If it doesn't have the literal meaning little horn in (Swiss) German, then it doesn't fit as diminutive. But if it does have that meaning, it would be a diminutive of Horn.
- As for snottebelleke, mantelzorgerke: As I searched at google books, there weren't any results for it, so it could fail WT:RFV. Then they doesn't belong in any entry. But if they are attested, I can't see any reason for not adding them as diminutives.
- -80.133.114.49 15:47, 22 January 2017 (UTC)
- Well Brabantian is mainly spoken, so one would need to go recording people (next Google project?) 62.235.174.135 16:50, 22 January 2017 (UTC)
- Songs and films also count as attestations, but unpublished recordings and Youtube clips don't. Crom daba (talk) 02:23, 23 January 2017 (UTC)
- De_Koninck_(bier), see bolleke. Of course, most Brabantian words have a diminutive, but it's rare to see them in print (Youtube would be fabulous actually for spoken lects!) As for unpublished recordings, I see the problem (really something for Google if you ask me with respect to documenting spoken lects). 62.235.174.135 09:04, 23 January 2017 (UTC)
- Well Brabantian is mainly spoken, so one would need to go recording people (next Google project?) 62.235.174.135 16:50, 22 January 2017 (UTC)
- ps.byATESTNalsoQUITEAFEW SN.DIMz'dstrugl as1.DICentryznocount(USAGduz!2.thoweNATIVSPEAKRSalno'owthey=formdd,noal=usdmuch(letalonin
ritin>shalwestartTAKEOUT CCsDIMtilshealATESTSm??(owmanyANGELSonpinzpoint gen,sai)INSTEDofADINCONTNT(evnSNpart=dirtpoorfulofomisnz(butlilwondrgivnabuv..:((~~
- I've changed two of Sven's posts to regular spelling. Lingo Bingo Dingo (talk) 13:00, 23 January 2017 (UTC)
- For words that get used in some kind of standard language, be it in Belgium or the Netherlands, I'd prefer putting the standard diminutive ahead, even if it's hard to attest. But I don't see much point in giving preference to a fictional standardised form if the word isn't used in standard lects to begin with. Lingo Bingo Dingo (talk) 13:00, 23 January 2017 (UTC)
atestatnVANDALIZDinfo:https://www.google.be/search?client=firefox-b-ab&q=dikkenekske&nfpr=1&sa=X&ved=0ahUKEwjUy-GQttjRAhWJOBoKHWvAAdEQvgUIGigB;nowCC"standed"rplacmnt:https://www.google.be/search?client=firefox-b-ab&q=dikkenekske&nfpr=1&sa=X&ved=0ahUKEwjUy-GQttjRAhWJOBoKHWvAAdEQvgUIGigB#q=dikkenekje&nfpr=1&start=10<ZILCH(naturaly,ashewasMESINinBRABentry(ivsenpplBLOKD4les..(ndaRUBISHstilstands:(https://en.wiktionary.org/wiki/dikkenek62.235.174.135 20:22, 23 January 2017 (UTC)
- a.SN-ke formsWAYmorIRegular,fe.baasje><bazeke<aditionalNED2v'm!62.235.178.189 13:48, 25 January 2017 (UTC)
morATESTATN(vers van de pers!:13, 2013 - Urbanus roept prins Laurent op het 'matteke' · Te weinig leraren in Antwerpse scholen door griepepidemie · Zeker zes doden bij schietpartij in ... Hele gemeente in shock na tragisch ongeluk Renske (4) - Vlaams ...<thezFORMSnedACOMODATEDinWT,somuch=clear(OWecanDEBAT~,sur(a.~ie,tjie etc81.11.219.200 14:49, 1 February 2017 (UTC)
Strengthening connections between entries
[edit]We have so many stubs, isolated pages, and one-way links that I'm wondering what we can do to strengthen the connections between our entries. So many of our Spanish entries are just a link to the plural and the English word. One idea is generating lists of one-way links within a language (related terms, et al), trans tables to entries, or (especially) between etymology sections (descendants sections are usually underpopulated/nonexistent), but I think we should discuss other ideas. For example, I can't find it, but isn't there a kind of subpage we can link to for related terms in the way we sometimes do for descendants? Is that worth pursuing for this purpose? What other ideas do y'all have? Ultimateria (talk) 12:41, 23 January 2017 (UTC)
- My entry-generation program tries to find related terms to add to new entries. It works like this: suppose entries X, Y and Z have a related terms section with a link to W; when the program generates the entry for W, it adds a related terms section with links to X, Y and Z.
- But in practice very few new entries ended up having automatic related terms, because existing related terms are usually links to entries that already exist. I could change it to find new related terms that could be added to existing entries, if there’s enough interest. — Ungoliant (falai) 13:52, 23 January 2017 (UTC)
- @Ultimateria: You probably know this but just in case you didn't or others didn't, Special:DeadendPages and Special:WantedPages are reports which have some relevance to what you're proposing. (biste has almost 5,000 incoming links!) —Justin (koavf)❤T☮C☺M☯ 18:14, 23 January 2017 (UTC)
- @Ungoliant: That's roughly what I was thinking; often a Romance verb will have 2-5 related entries, none of which link back to it. We could do something there. Especially with English basic lemmas which could link to dozens more pages, say, entries that link to them in the headword.
- @Koavf: I have used those pages at times, but the ones I'm even more concerned about are Special:OrphanedPages, and I think it would be helpful to also create lists of pages by language that are orphaned by other lemmas, ie, that aren't just linked to from their own inflections. Ultimateria (talk) 11:14, 24 January 2017 (UTC)
- @Ultimateria: You probably know this but just in case you didn't or others didn't, Special:DeadendPages and Special:WantedPages are reports which have some relevance to what you're proposing. (biste has almost 5,000 incoming links!) —Justin (koavf)❤T☮C☺M☯ 18:14, 23 January 2017 (UTC)
- One idea would be to populate related links from different wiktionary editions, so for Spanish entries take data from es.wikt. Doing this completely automated is tricky, but it could perhaps be implemented as a tool which runs on demand&supervised. – Jberkel (talk) 18:40, 23 January 2017 (UTC)
- This sounds like our entries need building out, in general -- any entry or POS subsection that just provides a single one-word gloss strikes me as quite deficient. How is the term used? What shades of meaning does it include? Are there slang senses? Etc., etc. ‑‑ Eiríkr Útlendi │Tala við mig 18:46, 23 January 2017 (UTC)
- I'm skeptical of any automatic solution. One thing that helps is to enable User:Dixtosa/nearby.js since related terms will often be nearby alphabetically. DTLHS (talk) 18:49, 23 January 2017 (UTC)
- I think using other wikts is an excellent idea, and I'm also skeptical of anything automated. As it is, I just expand Spanish entries as I find them, but to have a list of words that I could add to them would help me greatly at finding ones to expand and knowing which are its related terms. Ultimateria (talk) 11:14, 24 January 2017 (UTC)
- Does anyone do a dump run that set-subtracts our entries from the items enclosed in
{{l}}, sorted by the language parameter? That would serve to identify misspellings as well as exploit work already done that partially addresses the missing entry concern. Initially one could exclude multi-word terms. - Does anyone have a list of all of the tokens used in definitions (which are supposed to be in English) and in citations (which could be sorted by language of the citation)?
- I suspect that there are other similarly simple approaches. I don't have any intuition as to how resource-intensive these are, but they could be tested on subsets, such as words beginning with "q", "z", etc.. DCDuring TALK 13:36, 24 January 2017 (UTC)
- One-way links were identified systematically by Visviva's "Linkeration" system, which seems to have addressed many subtleties, judging by the subpages of User:Visviva/Linkeration. I don't know whether he would respond to an e-mail. DCDuring TALK 13:48, 24 January 2017 (UTC)
- Does anyone do a dump run that set-subtracts our entries from the items enclosed in
- I think using other wikts is an excellent idea, and I'm also skeptical of anything automated. As it is, I just expand Spanish entries as I find them, but to have a list of words that I could add to them would help me greatly at finding ones to expand and knowing which are its related terms. Ultimateria (talk) 11:14, 24 January 2017 (UTC)
AWB acess
[edit]User request I'd like to be able to use AutoWiki Browser here. As you can see from my most recent contributions, I've been filling in lists and sets in English and Spanish and having access will make it much easier to make the categories. —Justin (koavf)❤T☮C☺M☯ 19:29, 23 January 2017 (UTC)
- Done. DTLHS (talk) 22:54, 23 January 2017 (UTC)
Merger into Scandoromani
[edit]- Discussion moved to WT:RFM#Merger_into_Scandoromani.
Hi, I suppose it's an automatic process, so perhaps this is not the place to post. I'll provide an example:
In the English entry for 'pilgrim', the etymology section provides the following info : 'Middle English (early 13th century) pilegrim', yet plegrim's link directs you to an entry of its Norwegian homograph without any reference to Middle English.
I'd like to avoid it, so that I do not waste time following a link which will not provide any relevant info.
Thank you in advance.
avoid homograph hyperlink
[edit]Hi, I suppose it's an automatic process, so perhaps this is not the place to post. I'll provide an example:
In the English entry for 'pilgrim', the etymology section provides the following info : 'Middle English (early 13th century) pilegrim', yet pilegrim’s link directs you to an entry of its Norwegian homograph without any reference to Middle English.
I'd like to avoid it, so that I do not waste time following a link which will not provide any relevant info.
Thank you in advance. --Backinstadiums (talk) 09:00, 26 January 2017 (UTC)
- The problem of course, is that the page pilegrim doesn't have a Middle English entry yet. That happens all the time. There's no way to prevent links to pages that lack the corresponding language section, but if you go to your Preferences, under the Gadgets tab, you can select the box for "OrangeLinks: colour links orange if the target language is missing on an existing page". Then links to pages lacking the corresponding language section will appear in orange rather than blue, thus warning you ahead of time that there is, for example, no Middle English section at pilegrim. The link is still there, but the color keeps you from getting your hopes up. —Aɴɢʀ (talk) 09:38, 26 January 2017 (UTC)
- @Angr: Hi, this does not seem to work with Arabic script. As you can check, in its root page, 'Form I: رَسِلَ (rasila)' links to a page in which it's رُسُل (rusul) what appears, both rasila & rasul having the same homograph base form, namely رسل. I'd like to color these links as well if they lead to a page in which the specific form hasn't been added yet. Lastly, I'd like to change orange to green coloring, if possible, so that I can notice them better. PS: mention me when replying so that I am notified. thanks in advance. --Backinstadiums (talk) 18:59, 26 January 2017 (UTC)
- @Backinstadiums: It isn't Arabic script that's the problem. The orange-link function only looks to see if the language section is there, not if the exact form you're interested in is there. As for using green rather than orange, I imagine there's some way to change that on your own CSS page, but I couldn't begin to tell you how. —Aɴɢʀ (talk) 19:06, 26 January 2017 (UTC)
- @Angr: Regarding the arabic issue, should I post a new thread? can you come up with a solution for it? Regarding the colors, do I need a chunk of code? It's important for me as I suffer from a chromatic disfunction, and so it's difficult to distinguish orange and red, the latter being used usually for non-existent pages. — This unsigned comment was added by Backinstadiums (talk • contribs) at 13:17, January 26, 2017 (UTC).
- @Angr, Backinstadiums: I did "inspect" in Chrome, and I think the CSS class for the orange links is
.partlynew. You can use that to assign a color that's more visible for you. — Eru·tuon 20:17, 26 January 2017 (UTC)- @Erutuon:First of all, thanks for replying. Could you, please, post a step-by-step guideline on how to proceed? I know nothing about codes or CSS. — This unsigned comment was added by Backinstadiums (talk • contribs) at 14:43, January 26, 2017 (UTC).
- @Backinstadiums: It isn't Arabic script that's the problem. The orange-link function only looks to see if the language section is there, not if the exact form you're interested in is there. As for using green rather than orange, I imagine there's some way to change that on your own CSS page, but I couldn't begin to tell you how. —Aɴɢʀ (talk) 19:06, 26 January 2017 (UTC)
- @Angr: Hi, this does not seem to work with Arabic script. As you can check, in its root page, 'Form I: رَسِلَ (rasila)' links to a page in which it's رُسُل (rusul) what appears, both rasila & rasul having the same homograph base form, namely رسل. I'd like to color these links as well if they lead to a page in which the specific form hasn't been added yet. Lastly, I'd like to change orange to green coloring, if possible, so that I can notice them better. PS: mention me when replying so that I am notified. thanks in advance. --Backinstadiums (talk) 18:59, 26 January 2017 (UTC)
.partlynew { color: #hexcode or colorname; }- Okay, so go to your common.css page. Add a style rule like the one shown to the right.
.partlynewselects for HTML tags that haveclass="partlynew"in them. The brackets enclose style properties; the propertycoloris font color. You'll have to go to a page like the Web colors article on Wikipedia to select a color. That's the most basic answer. There are also ways to make visited links colored differently, but I don't have experience with that. (Also, just to note, I signed your posts for you.) — Eru·tuon 21:06, 26 January 2017 (UTC)- @Erutuon: Hi again, I do not why it doesn't work, have you tested it yourself? could you take a look? https://en.wiktionary.org/wiki/User:Backinstadiums/common.css --Backinstadiums (talk) 21:33, 26 January 2017 (UTC)
- @Backinstadiums: I added your code to my CSS page, and checked a link. It's getting overwritten by the default CSS. Add a space and
!importantafter the hex code, before the final;. That will make your color override the default. — Eru·tuon 21:42, 26 January 2017 (UTC)- @Erutuon: thank you so much, I does work now. Regarding the arabic script, where could I get a solution? --Backinstadiums (talk) 22:17, 26 January 2017 (UTC)
- @Backinstadiums: I added your code to my CSS page, and checked a link. It's getting overwritten by the default CSS. Add a space and
- @Erutuon: Hi again, I do not why it doesn't work, have you tested it yourself? could you take a look? https://en.wiktionary.org/wiki/User:Backinstadiums/common.css --Backinstadiums (talk) 21:33, 26 January 2017 (UTC)
- Okay, so go to your common.css page. Add a style rule like the one shown to the right.
@Backinstadiums: For a link to show whether a particular diacriticked form of an Arabic word is present in a page, someone would have to write a JavaScript function to look for the diacriticked form on the page and then add a CSS class to the link. Not sure if that's possible; I'm not very familiar with JavaScript. Lua (a module) might be able to do it too, though. I noticed there's a way to get the raw text of a page. But Lua would require a lot of processing power. — Eru·tuon 22:23, 26 January 2017 (UTC)
1000 Zulu entries :)
[edit]I managed to get Zulu up to 1000 entries. I just wanted to announce that. —CodeCat 18:37, 26 January 2017 (UTC)
- That's very good news, and much needed! Looking at Special:Statistics, African languages are pretty underrepresented here -- the ratio of 244 lemmas on Wiktionary versus 35 million native speakers for Amharic is a good example of this. Hopefully eventually we might get some native speakers to help out. — Kleio (t · c) 19:00, 26 January 2017 (UTC)
- Yay! It's always good to hear about good progress being made! I'm eagerly looking forward to the day when our coverage for every language is at least that good (it'll take a while though...we're still about 7,000,000 entries short... :P). Andrew Sheedy (talk) 19:03, 26 January 2017 (UTC)
- If anyone wants to help out with our coverage of African languages, I am accumulating a great deal of notes on paper but have yet to transfer them to Wiktionary! What I need is assistance in making more modules and templates, so even if you haven't studied these languages, you can help with the effort if you have technical knowledge. —Μετάknowledgediscuss/deeds 06:12, 27 January 2017 (UTC)
- I made several modules for Zulu, but they're not quite finished yet, in particular when it comes to tones. —CodeCat 14:04, 27 January 2017 (UTC)
- Hi @Andrew Sheedy, out of curiosity, is the 7,000,000 number based in fact or just a divine vision of how many entries are left? That sort of thing might be good to include in Wikistats—someone gave a presentation in the WMF January Metrics meeting about overhauling Wikistats, so maybe strike while the iron is hot. Icebob99 (talk) 05:40, 29 January 2017 (UTC)
- It's just a quick estimate of how many entries we'd need to add to reach a minimum of 1000 entries in every language. Since there are about 7500 known languages (including dead ones) and of those, about 120 have more than a thousand entries on Wiktionary, plus another 100 or so are well on their way to 1000, we have basically no entries for 7300 or so languages (so really, I underestimated, and we're about 7,300,000 entries short of having a minimum of 1,000 entries per language). So no, I don't have any special knowledge, nor did I put much effort into that estimate... Andrew Sheedy (talk) 06:27, 29 January 2017 (UTC)
- @Andrew Sheedy: A more humble goal but good starting point would be to compile the Swadesh lists of as many languages as possible and create the 207 entries every time. That might get people excited and interested in the project. --Barytonesis (talk) 17:51, 6 December 2017 (UTC)
- It's just a quick estimate of how many entries we'd need to add to reach a minimum of 1000 entries in every language. Since there are about 7500 known languages (including dead ones) and of those, about 120 have more than a thousand entries on Wiktionary, plus another 100 or so are well on their way to 1000, we have basically no entries for 7300 or so languages (so really, I underestimated, and we're about 7,300,000 entries short of having a minimum of 1,000 entries per language). So no, I don't have any special knowledge, nor did I put much effort into that estimate... Andrew Sheedy (talk) 06:27, 29 January 2017 (UTC)
- Hi @Andrew Sheedy, out of curiosity, is the 7,000,000 number based in fact or just a divine vision of how many entries are left? That sort of thing might be good to include in Wikistats—someone gave a presentation in the WMF January Metrics meeting about overhauling Wikistats, so maybe strike while the iron is hot. Icebob99 (talk) 05:40, 29 January 2017 (UTC)
- Well done, CodeCat! Excellent work! — I.S.M.E.T.A. 14:09, 15 February 2017 (UTC)
Display of Template:alter
[edit]I've gone and changed Module:alternative forms so that the dialect labels are enclosed in parentheses if the language doesn't have a transliteration module, but separated from the links by an n-dash if there is transliteration. (I created a new function Language:hasTranslit() in Module:languages to make this possible.) Some sort of a change to the display has been requested by @Mihia (October 2016) and @ObsequiousNewt (December 2015). — Eru·tuon 23:11, 26 January 2017 (UTC)
I would have added brackets in both cases, but it looks better (in my opinion) not having two parentheses in a row:
Hence, n-dash seemed the better option. Let me know your thoughts. — Eru·tuon 23:14, 26 January 2017 (UTC)
Conceivably, if there is disagreement about the display, we could add CSS classes that would allow people to remove the default display, and add their own preferred text before and after. — Eru·tuon 23:16, 26 January 2017 (UTC)
- In the past, I proposed removing the brackets from the transliteration instead. —CodeCat 23:17, 26 January 2017 (UTC)
- I like these changes. —JohnC5 05:46, 27 January 2017 (UTC)
- @Erutuon: I'm not super-thrilled by the inconsistency of display, but this is better than what we had before. How about doing away with parentheses for the dialect tags altogether, and separating them from the actual forms by em dashes in all cases? — I.S.M.E.T.A. 13:36, 15 February 2017 (UTC)
Pronuncify
[edit]There is a Github project to produce recordings for instant upload to Commons. At the end of recording, the snippets are to be self-categorized by commons:Category:Pronunciation.
The questions this raises for me include:
- Are these useful linguistic pronunciation categories?
- There is a distinct lack of documentation on how to categorize; is it possible to create a flow which usefully guides laypeople through categorizing their particular pronunciation?
- Is this valuable for Wiktionary?
- Amgine/ t·e 20:07, 27 January 2017 (UTC)
eliminate accents and parens from Proto-Balto-Slavic headwords
[edit]If you look in Category:Proto-Balto-Slavic lemmas, you see that some of the lemmas have accents in them, and some don't. In reality, all of them would have been accented on a given syllable, it's just that in many cases we don't know which syllable. Rather than the current random hodge-podge, I think we should consistently not include accents in the headwords. This would make it easier to locate the words, would add consistency and would be unlikely to cause very many (if any) homograph clashes. Benwing2 (talk) 19:27, 28 January 2017 (UTC)
- Also, cases like Reconstruction:Proto-Balto-Slavic/s(w)esō and Reconstruction:Proto-Balto-Slavic/tusk(t)jas should instead be split into two entries, one with the parenthesized letter and one without it, and linked using
{{alternative form of}}. Benwing2 (talk) 19:29, 28 January 2017 (UTC)
- @Benwing2: Please explain why “[t]his would make it easier to locate the words”. How do other online sources list reconstructed forms? I agree with your second idea, viz. that *s(w)esō, *tusk(t)jas, and their ilk should be split into *sesō and *swesō, *tuskjas and *tusktjas, etc. with one of each pair being lemmatised and the other thereof linking to the lemma with
{{alternative form of}}. — I.S.M.E.T.A. 13:55, 15 February 2017 (UTC)
- @Benwing2: Please explain why “[t]his would make it easier to locate the words”. How do other online sources list reconstructed forms? I agree with your second idea, viz. that *s(w)esō, *tusk(t)jas, and their ilk should be split into *sesō and *swesō, *tuskjas and *tusktjas, etc. with one of each pair being lemmatised and the other thereof linking to the lemma with
- @I'm so meta even this acronym Other online sources are listed alphabetically so the issue of accents doesn't apply. The thing is that often different sources disagree about where the accents go or even whether the position of the accent is reconstructible at all -- then what do we do? As far making it easier to locate the words: if someone is trying to autocomplete a word, (1) it's often hard to type accents, and (2) they have to know to check the version with the accent and without it, esp. if the accent occurs near the beginning of a word. Furthermore, someone entering the form as a link in another page is less likely to get the lemma right. Benwing2 (talk) 02:56, 16 February 2017 (UTC)
- @Benwing2: I admit that I don't understand these issues sufficiently to opine on them with confidence, but from what I've read in this section, I'm inclined to agree with you (as long as redirects are included from all accented-PAGENAME forms to the corresponding unaccented-PAGENAME forms). — I.S.M.E.T.A. 08:29, 6 March 2017 (UTC)
- I see no reason to do this. There's the same "hodgepodge" for PIE and other languages with accents as well. We should provide what information we know. —CodeCat 20:23, 28 January 2017 (UTC)
- Yes and I think this should be done for PIE as well. As for "other languages", this issue doesn't apply to modern languages. Either they do or don't include the accents but in both cases it's standardized and doesn't depend on someone's random theory of where the accents go. Benwing2 (talk) 20:59, 28 January 2017 (UTC)
- I'm not opposed to removing accents from PBS and PIE page names as long they can remain in headword lines. We can treat them the same as macrons in Latin, complete with diacritic stripping in linking templates. —Aɴɢʀ (talk) 21:08, 28 January 2017 (UTC)
- Like Angr I would be fine with accents being removed from PIE entry names if they are displayed in headword lines. In fact, I like the idea, because it would make entry names more consistent. — Eru·tuon 21:20, 28 January 2017 (UTC)
- Yes, this is exactly what I am proposing -- remove the accents from the page names but keep them in headword lines, and do diacritic stripping in links. Benwing2 (talk) 01:47, 29 January 2017 (UTC)
- I oppose this. —CodeCat 18:17, 31 January 2017 (UTC)
- Is CodeCat the only person who opposes? If so I may put this to a vote. Benwing2 (talk) 01:37, 1 February 2017 (UTC)
- If there is a possibility that many words can be reconstructed only without the accents, then I strongly support, otherwise I'm neutral. --WikiTiki89 15:14, 1 February 2017 (UTC)
- I also oppose the removal of the accents from PIE. —JohnC5 17:41, 1 February 2017 (UTC)
- @JohnC5 I'm not proposing removing accents from links or headwords, only from the lemma (i.e. from the page name). Benwing2 (talk) 02:57, 16 February 2017 (UTC)
- @Wikitiki89 There are lots of words where the accent isn't clear, and different authors often differ radically in how they reconstruct the position of the accent. Benwing2 (talk) 02:59, 16 February 2017 (UTC)
- @Benwing2: I'm aware of what you are proposing. I oppose the removal of accents from the pagenames in PIE. —JohnC5 04:26, 16 February 2017 (UTC)
- @JohnC5: Do you have an opinion for PBS? --WikiTiki89 15:09, 16 February 2017 (UTC)
- @Benwing2: I like the accents but am fine either was in PBS. —JohnC5 15:33, 16 February 2017 (UTC)
- @Benwing2: There's a big difference between an alternative reconstruction with a different accent, and an unknown accent. Alternative reconstruction means we have evidence pointing to different scenarios, while an unknown accent would mean we don't have evidence about the accent. It's the unknown case that's problematic if accents are required for pagenames. Alternative reconstructions can be resolved with alternative form entries. I still see no downside to removing accents from pagenames in either PIE or PBS, so if there is a need to so, then I support removing them. --WikiTiki89 15:14, 16 February 2017 (UTC)
- A good thing then that accents are not required for pagenames. They're included if known. —CodeCat 16:38, 16 February 2017 (UTC)
- The problem is that "known" is not a binary variable. Kortlandt may claim an accent is known but someone else like Matasovic may completely disagree. AFAIK the state of Proto-Balto-Slavic accentation is somewhat unsettled (even more so for Proto-Slavic). Benwing2 (talk) 01:56, 17 February 2017 (UTC)
Arabic patterns
[edit]Hi, it would improve inmensely the Arabic dictionary to add categories for the different patterns used in terms which lack them. For example, for the noun رَئِيس (pl. رُؤَسَاء) the following information shows up 'From the root ر ء س (r-ʾ-s) of رَأْس (raʾs, “head”)', yet marking the pattern with which it's form, namely فَعِيل (pl. فُعَسَاء), specially for broken plurals, would help those beginning to learn the language to recognize patterns, just as happens with the conjugation of verbs which is automatically added in each entry. Thanks in advance. --Backinstadiums (talk) 16:38, 31 January 2017 (UTC)
- We have a template
{{transfix}}for this already. It just needs to be added to entries. —CodeCat 18:18, 31 January 2017 (UTC)- @CodeCat Hi, I am a simple user, so I have no idea about it. Can it be implemented automatically for every single term, including verbal nouns? Where should I request it?
- No, sadly. You have to add it manually to every entry. —CodeCat 19:22, 31 January 2017 (UTC)
- @CodeCat and could it be created with some lines of code? Here's some academic work on it: http://www.attiaspace.com/
- What is the pattern of رَأْس actually? Is it -a--? —CodeCat 19:35, 31 January 2017 (UTC)
- The pattern is "faʿl", from the root consonants where each root consonants are represented by "f-ʿ-l". The patterns for the two plural forms of رَأْس (raʔs) are 1. "fuʿūl" رُؤُوس (ruʔūs) and 2. "ʾafʿul" أَرْؤُس (ʔarʔus). --Anatoli T. (обсудить/вклад) 21:35, 31 January 2017 (UTC)
- Why are the root consonants included in the pattern? That seems counterintuitive to me. —CodeCat 21:40, 31 January 2017 (UTC)
- The pattern is "faʿl", from the root consonants where each root consonants are represented by "f-ʿ-l". The patterns for the two plural forms of رَأْس (raʔs) are 1. "fuʿūl" رُؤُوس (ruʔūs) and 2. "ʾafʿul" أَرْؤُس (ʔarʔus). --Anatoli T. (обсудить/вклад) 21:35, 31 January 2017 (UTC)
- What is the pattern of رَأْس actually? Is it -a--? —CodeCat 19:35, 31 January 2017 (UTC)
- @CodeCat Hi, I am a simple user, so I have no idea about it. Can it be implemented automatically for every single term, including verbal nouns? Where should I request it?
- (Before E/C) It's doable. The verb patterns are already automated - User:Benwing2's work. See also Wiktionary:Beer_parlour/2017/January#Arabic_consonant_patterns. One needs to separate loanwords, which don't have patterns and may contain any number of consonants and can be confused with patterns.
- (After E/C). This is how Arabic (and other semitic) patterns are described by grammarians - for declensions, conjugations, forming verbal nouns, plural forms, etc. Why is it counterintuitive? --Anatoli T. (обсудить/вклад) 21:47, 31 January 2017 (UTC)
- @CodeCat If you look at Appendix:Arabic verbs, it's all based on root patterns where consonants ف ع ل (f-ʿ-l) are used for each verb form, perfective and imperfective. --Anatoli T. (обсудить/вклад) 21:52, 31 January 2017 (UTC)
- @Atitarev, Benwing2: Do you think a function detecting the pattern of a word would need the root to be input into the headword template, or could it automatically detect both root and pattern? — Eru·tuon 21:57, 31 January 2017 (UTC)
- My guess is that just the (e.g. noun) headword with plural forms would provide the plural forming patterns but Benwing2 would know better. With verbs, the root letters are not supplied as a separate parameter. --Anatoli T. (обсудить/вклад) 22:02, 31 January 2017 (UTC)
- @Erutuon In some cases it's possible to auto-detect both root and pattern from the noun given the vocalized form, but there are a whole lot of cases where it isn't easy and may be impossible, esp. when there are weak root letters involved. For example, there's no real way to autodetect the radicals of a word like صِلَة (ṣila, “link”), from و ص ل (w ṣ l), or بَاب (bāb, “door”) from ب و ب (b w b). It would be another story if the root were specified. Potentially something could be written to autodetect the easy cases and throw an error if it can't autodetect, requiring that the root be specified. Even for verbs, the verb form (I, II, III, IV, etc.) must be specified, else many verbs are ambiguous. Benwing2 (talk) 04:05, 1 February 2017 (UTC)
- @Benwing2 I suspected there might be a problem with assimilated, weak, defective, geminated, hamzated and quadrilateral roots making the detections unreliable. Loanwords would further complicate it. If the root letters are supplied in the etymology, they could be used to determine the pattern, no? --Anatoli T. (обсудить/вклад) 04:14, 1 February 2017 (UTC)
- @Atitarev I think so. There are a lot of special cases with nouns so it would be complicated, but probably doable. Benwing2 (talk) 04:17, 1 February 2017 (UTC)
- @CodeCat One of the reasons for using root letters ف ع ل (f ʕ l) is that it helps indicate roots where a letter occurs more than once. For example, the فَعَّال (faʕʕāl) pattern has a doubled consonant in the middle of it, and its plural has the pattern فَعَاعِيل (faʕāʕīl), where a vowel breaks up the two parts of the doubled consonant. If it were simply indicated as -a-ā-ī- it wouldn't be obvious that the 2nd and 3rd consonants are always the same in this pattern. Benwing2 (talk) 04:21, 1 February 2017 (UTC)
- @Atitarev: Root letters in the etymology? I was thinking that root and pattern detection would happen in the headword template. — Eru·tuon 04:25, 1 February 2017 (UTC)
- It turns out to be too hard or impossible. A combination of root letters from the etymology's
{{ar-root}}with the rest coming from the headword would do the trick. You should follow up the implementation with Benwing2, though.--Anatoli T. (обсудить/вклад) 04:38, 1 February 2017 (UTC)
- It turns out to be too hard or impossible. A combination of root letters from the etymology's
- @Benwing2 I suspected there might be a problem with assimilated, weak, defective, geminated, hamzated and quadrilateral roots making the detections unreliable. Loanwords would further complicate it. If the root letters are supplied in the etymology, they could be used to determine the pattern, no? --Anatoli T. (обсудить/вклад) 04:14, 1 February 2017 (UTC)
- @Erutuon In some cases it's possible to auto-detect both root and pattern from the noun given the vocalized form, but there are a whole lot of cases where it isn't easy and may be impossible, esp. when there are weak root letters involved. For example, there's no real way to autodetect the radicals of a word like صِلَة (ṣila, “link”), from و ص ل (w ṣ l), or بَاب (bāb, “door”) from ب و ب (b w b). It would be another story if the root were specified. Potentially something could be written to autodetect the easy cases and throw an error if it can't autodetect, requiring that the root be specified. Even for verbs, the verb form (I, II, III, IV, etc.) must be specified, else many verbs are ambiguous. Benwing2 (talk) 04:05, 1 February 2017 (UTC)
- My guess is that just the (e.g. noun) headword with plural forms would provide the plural forming patterns but Benwing2 would know better. With verbs, the root letters are not supplied as a separate parameter. --Anatoli T. (обсудить/вклад) 22:02, 31 January 2017 (UTC)
@Benwing2, @Atitarev, @CodeCat, @Erutuon Please take a look, there's a lot of work already done, https://sourceforge.net/projects/arabicpatterns/, so the most common 'assimilated, weak, defective, geminated, hamzated and quadrilateral roots' are already taken into account in opensource academic works. What do you say? --Backinstadiums (talk) 23:35, 1 February 2017 (UTC)
- @Backinstadiums When you use
{{ping}}, you have to sign your post, otherwise it won't work. Your link is not very useful, especially for the technical solution to be made. These type of roots are already covered by verb conjugation modules. As discussed, it's doable if both the root consonants and headwords are used but it's up to User:Benwing2 or someone else knowledgeable in both Lua and some Arabic to implement it. --Anatoli T. (обсудить/вклад) 23:25, 1 February 2017 (UTC)- @Atitarev: There's a way for one template to get parameters from another template? How would that work? I think I'm going to try to write a function at Module:User:Erutuon/sandbox. — Eru·tuon 02:33, 2 February 2017 (UTC)
- I'm afraid you have to ask at WT:GP. I am not writing modules any more. --Anatoli T. (обсудить/вклад) 02:44, 2 February 2017 (UTC)
- Ah, okay. I'll write a function first and then ask that question. — Eru·tuon 02:48, 2 February 2017 (UTC)
- One template can't easily get the params of another. You'd have to copy the params, perhaps by bot. Benwing2 (talk) 03:40, 2 February 2017 (UTC)
- Ah, okay. I'll write a function first and then ask that question. — Eru·tuon 02:48, 2 February 2017 (UTC)
- I'm afraid you have to ask at WT:GP. I am not writing modules any more. --Anatoli T. (обсудить/вклад) 02:44, 2 February 2017 (UTC)
- @Atitarev: There's a way for one template to get parameters from another template? How would that work? I think I'm going to try to write a function at Module:User:Erutuon/sandbox. — Eru·tuon 02:33, 2 February 2017 (UTC)
- @Erutuon Hi, I just want to ask whether you were able to write that 'function', as well as say that I am willing to help with the work as long as I have the skills required. Regards. --Backinstadiums (talk) 10:20, 15 February 2017 (UTC)
- @Backinstadiums: I created the beginnings of a function in Module:User:Erutuon/sandbox. It divides a word into consonants and vowels. I'm still thinking about how to create the pattern recognition part of the function. — Eru·tuon 18:05, 15 February 2017 (UTC)
- @Erutuon: Dear pal, how is the project going? I've checked your 'Testcases', and it seems fairly good, so do not hesitate to ask me for whatever you might need as long as I can provide it, especially linguistic resources. --Backinstadiums (talk) 12:28, 1 April 2017 (UTC)